GeneFace 使用技巧与创意玩法集锦
我一开始对 GeneFace 其实没什么期待,毕竟它不像 SadTalker 那样满地都是教程。但真跑起来后我发现,它是目前我试过最像“电影后期”的 AI 动画工具。嘴型精度高、头部稳定、而且可以和多种模型组合搭配。
这篇文章我就把这些“踩过的坑、调过的参、玩过的骚操作”都整理一遍,希望你看完之后能少走点弯路。
1 一、准备素材:图像 + 音频 + 骨骼动画(可选)
GeneFace 有点不一样,它本质上是走 3D 动画合成路径,所以你能做的事情更多,但要求也更高。
基本素材准备三件套:
- 人脸图像(清晰度越高越好)
- 音频
.wav格式(采样率 16k 最稳) - 可选动画骨骼参数(可以用官方 demo 数据)
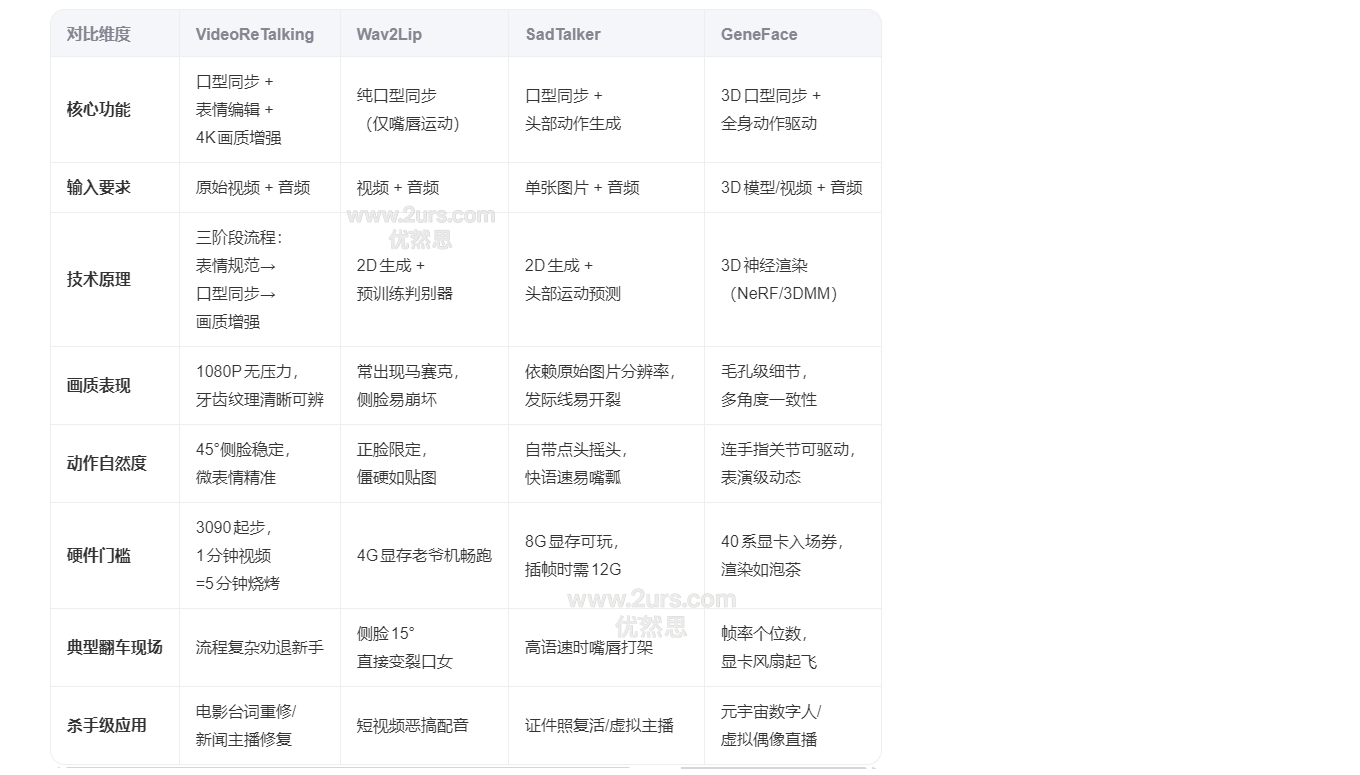
图像建议裁成 512x512,如果你之前看过这篇教程:video-retalking_wav2lip_sadtalker__geneface对比,你会知道 GeneFace 对人脸输入的依赖度其实是最高的。
2 二、安装部署技巧
GeneFace 的部署对新手有点硬核,这里是我踩过坑之后总结的两个小技巧:
2.1 1. 用 Conda 管理环境
conda create -n geneface python=3.10
conda activate geneface
pip install -r requirements.txt如果你 torch 和 torchvision 一直装不上,建议提前固定好版本,比如:
pip install torch==2.0.1 torchvision==0.15.22.2 2. 有显卡就大胆开 FP16
如果你用的是 30 系列或以上的 NVIDIA 显卡,一定要加 --use_fp16,推理时间几乎能节省 30%。
3 三、核心命令解析
你要跑一段完整的流程其实不复杂:
python inference.py --img_path ./inputs/face.jpg \
--audio_path ./inputs/audio.wav \
--output_path ./outputs/ \
--use_fp16你也可以加上 --ref_video 参数,用别人的头部动作来驱动自己的图像,能做出类似“换脸口播”的效果。
4 四、创意玩法集锦(纯干货)
4.1 1. AI 虚拟主播系统的核心模块
配合 GPT-SoVITS 或 MuseTalk,你可以实现一个从文本 → 音频 → 视频全自动生成系统。文本写好一段文案,一键生成说话视频,我已经用它试过三个项目场景了。
如果你还没了解过声音模型训练,可以看我这篇:gpt-sovits声音模型训练
4.2 2. 视频配音同步替换
GeneFace 不只是嘴动准,它生成的是标准视频序列,你可以直接将旧视频的配音替换为新语音,再用 GeneFace 重新生成口型对齐版本,适合做“影视重配音”。
4.3 3. 和其他口型工具混合使用
GeneFace 的缺点是“生成速度偏慢”,这时候可以先用 SadTalker 或 video-retalking 出快速预览,再换成 GeneFace 渲染正式版本。
组合玩法不仅提高效率,还能保留各自优点,比如:
- SadTalker:头部动态丰富但不稳定
- GeneFace:嘴型精准但略慢
- video-retalking:适合快速出稿做剪辑预览
如果你对“精度”和“画面稳定”有要求,那 GeneFace 是目前最强之一。 门槛也确实不低,部署略麻烦、推理慢一点,但结果非常惊艳。 最适合用在“中大型项目”和“高质量短视频”上,但别指望它拿来量产日更。
5 VideoReTalking、Wav2Lip、SadTalker、GeneFace 的核心区别对比