SadTalker 实战教程:AI 驱动口型同步全流程
目录
你是不是也刷到过那种“照片说话”的短视频,嘴型居然还能对上声音?别以为这是哪种高级深度伪造,很多其实就是用的 SadTalker。
这个工具不需要你有深厚的机器学习背景,准备好一张照片、一段音频,稍微调调参数,就能把图“复活”。
我自己在跑完之后也觉得:难的不是用它,而是踩坑全在环境搭建上。
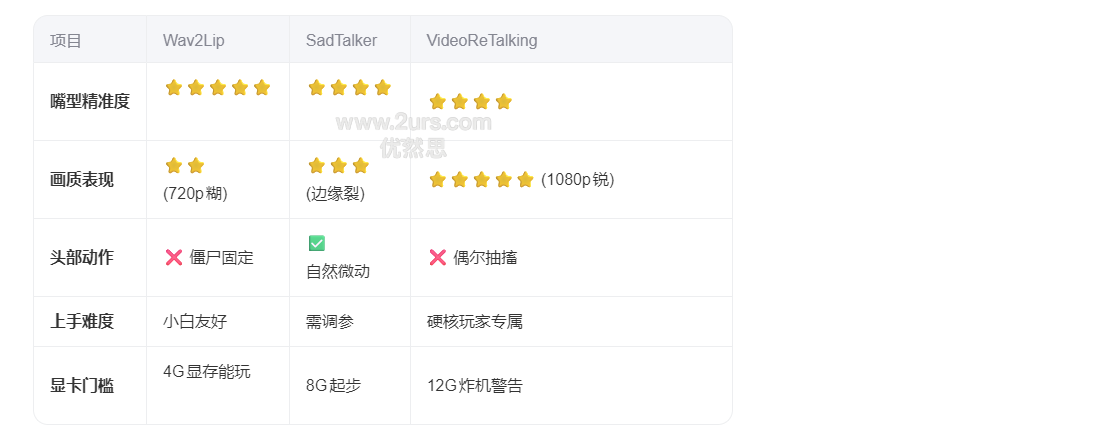
video-retalking wav2lip sadtalker区别:
1 第一步:环境准备,踩坑集中区
如果你是 Windows 用户,建议用 Anaconda 新建环境,避免污染系统。
conda create -n sadtalker python=3.9
conda activate sadtalker接着克隆仓库:
git clone https://github.com/OpenTalker/SadTalker.git
cd SadTalker
pip install -r requirements.txt要注意几个版本问题:
torch推荐用 1.13 或以上ffmpeg是硬性依赖,没装别想跑- 如果报
xformers错误,直接注释掉对应模块即可(没啥大用)
2 第二步:准备素材,照片+音频
照片要求:
- 越清晰越好,最好 512x512 正面照
- 不要复杂背景,最好是纯色
音频要求:
- 格式必须是
.wav(用 Audacity 转一下) - 时长尽量控制在 10~30 秒内
- 中文也支持,但要有清晰断句(不然嘴型很怪)
我之前用的是一段配音工具生成的音频,配合自己头像,效果惊艳。
3 第三步:命令行运行,推荐参数配置
核心命令长这样:
python inference.py --driven_audio path/to/audio.wav \
--source_image path/to/image.jpg \
--result_dir ./results \
--preprocess full \
--enhancer gfpgan \
--still解释下几个关键参数:
--preprocess:推荐用full,对齐最精准--enhancer:用gfpgan会自动修复脸部细节--still:强烈建议加上,不然人头会晃得像打摆子
别问我怎么知道的,试了十几次才发现这一行不加,出来的视频跟惊悚片似的……
4 第四步:效果优化建议
视频生成后你可能觉得嘴对得还不够准,有几个办法可以改善:
- 换音频:有些音频节奏太快,SadTalker 对不上
- 换图:嘴部闭合、清晰度低的图都不太好用
- 后期微调:可以导入到
video-retalking做二次修正 👉 延伸阅读:video-retalking_wav2lip_sadtalker__geneface对比
SadTalker 尤其适合以下场景:
- 做 AI 虚拟人项目(省视频成本)
- 内容创作者生成“口播”视频
- 想让老照片开口讲述故事(文案+感情加持)
不过它也有缺点:
- 嘴型对得不如
Wav2Lip准确(但视觉冲击力更强) - 模型运行慢,5秒音频渲染大约1分钟
所以,如果你追求画面表现而不是“口型精度”,SadTalker 是绝对首选。
- 要速度:Wav2Lip怼正脸,别嫌画质烂
- 要演活:SadTalker摇脑袋,记得裁掉炸毛发型
- 要高清:VideoReTalking硬刚,备好消防栓给显卡降温