title: “自留地log-twiter”
date: “2023-01-23”
draft: true
hiddenFromHomePage: true
categories:
- “日记”
tags:
- “日记”
url: “/goals/191”
1
2
| https://twitter.com/i/status/1447067030008385539 不可以;
https://twitter.com/willowhalliwell/status/1452460936116244482 可以 https://twitter.com/i/status/1408614729413767172
|
https://twittervideodownloader.com 可用 预估日均IP≈288000
https://twitter.iiilab.com/ 可用
https://www.savetweetvid.com/zh 可用
https://twitterxz.com/
https://xunlangbot.com/download
https://www.getmytweet.com/down.php
0xNima/Twideo: Simple Telegram Bot for downloading videos from Twitter via their links (github.com) 可以用 机器人
abraham/twitteroauth: The most popular PHP library for use with the Twitter OAuth REST API. (github.com) twitter新接口
jellydn/twt-dl-cli: The easiest way to download any Twitter video from CLI (github.com) 待测试
FixTweet/FixTweet: Embed Twitter videos, polls, and more on Discord and Telegram (github.com)
https://www.getfvid.com/zh/twitter
https://xxtwitter.com/zh-CN/i/status/1408614729413767172
https://www.getmytweet.com/zh/down.php
hitomi_downloader_GUI
https://github.com/amakavanessa/sm-video-downloader
Chimise/video_downloader: Download video from social media websites like Twitter, LinkedIn, Youtube, Facebook and many others. (github.com)
okikio/inthistweet: ✨ Futuristic ✨ twitter image, gif and video downloader. Enter a Tweet URL, click search, and download the image/videos in it. (github.com)
shiningw/ncdownloader: An easy-to-use web interface for Aria2 and Youtube-dl (downloading bittorrents, videos from twitter, youtube and the likes)运行在nextcloud下的多功能下载工具(Aria2 and youtube-dl) (github.com)
1 后端输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| {
"formats": [
{
"resolution": "478x270",
"url": "https://video.twimg.com/ext_tw_video/1452460902083661829/pu/vid/478x270/6AtBRkPMSWgLIkYb.mp4?tag=12"
},
{
"resolution": "638x360",
"url": "https://video.twimg.com/ext_tw_video/1452460902083661829/pu/vid/638x360/m6TIdEVaI9fqPYVX.mp4?tag=12"
},
{
"resolution": "1136x640",
"url": "https://video.twimg.com/ext_tw_video/1452460902083661829/pu/vid/1136x640/qDTcBUqO1aIF69fS.mp4?tag=12"
}
],
"thumb": "https://pbs.twimg.com/ext_tw_video_thumb/1452460902083661829/pu/img/FxyfzXI3ew2xLTTz.jpg?name=small",
"title": "BLACK LIVES MATTER - Logan Roy"
}
|
2
def parse_video_url(video_link):
使用正则表达式或其他方式解析视频地址
video_link = request.json[“video_link”]
##会先尝试请求 v2,如果请求成功则直接返回结果;如果 v2 请求失败,那么会尝试请求 v1,如果请求成功则返回结果;如果 v1 请求失败,那么返回 “Error occurred”。
url_v2 = “http://127.0.0.1:8010/api/process/v2”
params = {‘video_link’: video_link}
response = requests.get(url_v2, params=params)
if response.status_code == 200:
return response.json()
else:
url_v1 = "http://127.0.0.1:8010/api/process/v1"
response = requests.get(url_v1, params=params)
if response.status_code == 200:
return response.json()
else:
return "Error occurred"
可以再添加一个请求 v3 的逻辑,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| def parse_video_url(video_link):
# 使用正则表达式或其他方式解析视频地址
video_link = request.json["video_link"]
url_v2 = "http://127.0.0.1:8010/api/process/v2"
params = {'video_link': video_link}
response = requests.get(url_v2, params=params)
if response.status_code == 200:
return response.json()
else:
url_v1 = "http://127.0.0.1:8010/api/process/v1"
response = requests.get(url_v1, params=params)
if response.status_code == 200:
return response.json()
else:
url_v3 = "http://127.0.0.1:8010/api/process/v3"
response = requests.get(url_v3, params=params)
if response.status_code == 200:
return response.json()
else:
return "Error occurred"
|
这样,如果 v2 请求失败,就会尝试请求 v1,如果 v1 请求失败,就会尝试请求 v3。如果 v3 请求失败,就会返回错误信息 “Error occurred”。
3 启动报错:raise AssertionError(
AssertionError: View function mapping is overwriting an existing endpoint function: process
如果改为 @app.route(’/api/process2/v2’, methods=[‘GET’])
def process2():
则报错:GET /api/process/v2?video_link=https%3A%2F%2F
请问怎样优化下 同时存在 v1 v2
process() 函数名被重复定义了两次,导致路由发生冲突。可以分别改为 process_v1() 和 process_v2(),并在 parse_video_url() 中分别调用即可。 正确的是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| # 这个代码会先尝试请求 v2,如果请求成功则直接返回结果;如果 v2 请求失败,那么会尝试请求 v1,如果请求成功则返回结果;如果 v1 请求失败,那么返回 “Error occurred”。
def parse_video_url(video_link):
# 使用正则表达式或其他方式解析视频地址
video_link = request.json["video_link"]
url_v2 = "http://127.0.0.1:8010/api/process/v2"
params = {'video_link': video_link}
response = requests.get(url_v2, params=params)
if response.status_code == 200:
return response.json()
else:
url_v1 = "http://127.0.0.1:8010/api/process/v1"
response = requests.get(url_v1, params=params)
if response.status_code == 200:
return response.json()
else:
return "Error occurred"
def gv():
# 使用正则表达式或其他方式解析视频地址
pass
def get_download_url(video_url):
# 使用第三方库或其他方式获取下载地址
pass
@app.route('/api/process/v1', methods=['GET'])
def process_v1():
url = request.args.get('video_link')
if not url:
return jsonify({'error': 'Missing url'}), 400
#result = run(["./yt-dlp", url, "--dump-json", "--no-check-certificates", "--no-warnings"], stdout=PIPE, stderr=PIPE)
result = run(["./yt-dlp", url, "--dump-json", "--no-check-certificates", "--no-warnings"], stdout=PIPE, stderr=PIPE)
if result.returncode != 0:
return jsonify({'error': result.stderr.decode()}), 500
videos = [json.loads(line)['url'] for line in result.stdout.decode().split('\n') if line]
print(result)
print(videos)
#result = (result.stdout.decode())
result = json.loads(result.stdout.decode())
#print(result)
title = result['title'][:30]
formats = [{'url': item['url'], 'resolution': item['resolution']} for item in result['formats'] if item['protocol'] == 'https']
thumb = next((item['url'] for item in result['thumbnails'] if item['id'] == 'small'), None)
data = {'title': title, 'formats': formats, 'thumb': thumb}
print(data)
return jsonify(data)
@app.route('/api/process/v2', methods=['GET'])
def process_v2():
url = request.args.get('video_link')
if not url:
return jsonify({'error': 'Missing url'}), 400
from TwitterMedia import TwitterMedia
downloader = TwitterMedia()
tweet = downloader.fetch_media(url)
if tweet is not None:
print(tweet)
else:
print("fetch_media 函数返回 None") # return jsonify({'error': result.stderr.decode()}), 500
return tweet
if __name__ == "__main__":
app.run(debug=True,host='127.0.0.1', port=8010 )
|
前端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
|
<!DOCTYPE html>
<html lang="zh-cmn-Hans">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, shrink-to-fit=no"/>
<meta name="renderer" content="webkit"/>
<meta name="force-rendering" content="webkit"/>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"/>
<meta name="description" content="Twitter视频下载在线 - 保存Twitter 视频.fb是一个免费的工具,输入twitter视频rul,或者git的url点击就可下载任何Twitter视频和GIF。 免费,快速和易于使用。">
<meta name="keywords" content="twitter视频下载软件,保存twitter视频,twitter视频,tweet视频下载器,社交视频下载器,下载twitter视频,twitter下载视频,从twitter下载gif,飞步网">
<meta property="og:type" content="website" />
<meta property="og:title" content=" 从Twitter下载视频和GIFS的最佳方式" />
<meta property="og:description" content="快速的从Twitter下载视频,只需点击一下即可免费下载到您的手机上或计算机上" />
<title>Twitter视频下载</title>
<link rel="icon" type="image/png" href="/favicon.ico">
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/mdui@1.0.0/dist/css/mdui.min.css"/>
<script src="https://cdn.jsdelivr.net/npm/mdui@1.0.0/dist/js/mdui.min.js"></script>
<script src="https://cdn.bootcss.com/jquery/2.1.4/jquery.min.js"></script>
</head>
<body class="mdui-theme-primary-indigo mdui-theme-accent-pink">
<style>
/* Add a version number to solve the cache problem */
<?php echo file_get_contents( get_template_directory() . '/style.css' ); ?>
::selection {
background: rgba(0, 149, 255, .1);
}
body:before {
top: 0;
left: 0;
right: 0;
bottom: 0;
opacity: .3;
z-index: -1;
content: "";
position: fixed;
background-image: linear-gradient(135deg, #CE9FFC 10%, #7367F0 100%);
}
.mdui-textfield-input {
float: left;
width: 75%;
text-transform: none;
}
#video_link {
width: 330px;
height: 52.1px;
}
#download_btn {
width: 108px;
height: 52.1px;
background-color: darkgreen;
color: white;
}
.mdui-btn {
/* Remove width property */
}
.mdui-container {
max-width: 900px;
margin-top: 1em;
margin-bottom: 1em;
}
.mdui-btn,
.mdui-fab {
min-width: 0px;
}
.mdui-card {
opacity: 1.0;
padding: 1em;
border-radius: 1px;
display: flex;
flex-wrap: wrap;
}
.down .mdui-btn {
width: auto;
margin-bottom: 0.5em;
display: flex;
justify-content: center;
align-items: center;
}
.mdui-card-content {
display: flex;
flex-direction: row;
justify-content: space-between;
align-items: center;
flex: 1;
padding: 1px;
}
.down {
display: flex;
justify-content: center;
width: auto;
}
.mdui-card-primary-title {
font-size: 14px;
}
.mdui-card-footer {
text-align: center;
margin-top: 2em;
}
.mdui-card-footer p {
margin-bottom: 1em;
}
.qrcode-div {
display: inline-block;
margin: 1em;
}
.qrcode-div canvas {
max-width: 100%;
height: auto;
}
.thumb-img {
max-width: 50%;
display: block;
}
@media (max-width: 600px) {
.mdui-card-primary-title {
text-align: center;
margin-bottom: 1em;
}
#form_url {
display: flex;
flex-direction: column;
align-items: center;
}
#download_btn {
margin-top: 1em;
}
.mdui-card-content {
flex-direction: column;
align-items: flex-start;
}
.down {
margin-top: 1em;
display: flex;
justify-content: center;
}
.mdui-card-primary-title {
font-size: 14px;
}
.thumb-img {
max-width: 100%;
}
}
@media (min-width: 601px) {
#video_link {
width: 530px;
height: 52.1px;
}
.mdui-card {
display: flex;
}
.mdui-card-media {
display: flex;
justify-content: center;
align-items: center;
}
.mdui-card-primary-title {
flex: 1;
padding-left: 1em;
}
.down {
display: block;
margin-top: 10px;
}
.thumb-img {
max-width: 60%;
}
}
</style>
<main class="mdui-container">
<div class="mdui-card">
<div class="mdui-card-media">
<img class="thumb-img1" src="https://cdn.jsdelivr.net/gh/5ime/img/avatar.jpg"/>
</div>
<div class="mdui-card-primary">
<h1 class='mdui-text-center'>Twitter视频下载软件</h1>
<div class="mdui-typo">
<p><strong>温馨提示 </strong>右击twitter视频, 复制视频地址到下面输入框。点击进入页面。<u></u><small> </small></p>
<p>选择对应分辨率的下载按钮 右击另存为视频。 或者点击按钮,打开视频后直接保存。<u></u><small></small></p>
</div>
</div>
</div>
<div id="container" class="mdui-card mdui-center">
<form id="form_url">
<label for="video_link"> </label>
<input type="text" id="video_link" name="video_link" onfocus="this.value=''" value="请输入视频页面url 比如: https://twitter.com/i/status/1580927207987257344" style="color: gray;">
<button id="download_btn" type="button">Download</button>
<p id="error_message" style="display:none">Uh-Oh! 可能是没有,请更换url</p>
</form>
</div>
<script>
document.getElementById("download_btn").addEventListener("click", async function() {
document.getElementById("download_btn").innerText = "Downloading...";
document.getElementById("download_btn").setAttribute("disabled", "disabled");
const video_link = document.getElementById('video_link').value;
const data = { video_link: video_link };
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(data)
};
const response = await fetch('/download', options);
if (!response.ok) {
document.getElementById("error_message").style.display = "block";
download_btn.innerText = "Downloaded";
download_btn.removeAttribute("disabled");
return;
}
try {
const jsonData = await response.json();
// Remove form_url
document.getElementById("form_url").style.display = "none";
// create and add the thumbnail image
const thumb = document.createElement("img");
const imageDiv = document.createElement("div");
thumb.src = jsonData.thumb;
thumb.classList.add("thumb-img");
imageDiv.classList.add("mdui-card-media");
imageDiv.appendChild(thumb);
// create and add the title
const title = document.createElement("div");
const titleDiv = document.createElement("div");
titleDiv.classList.add("mdui-card-primary-title");
title.innerHTML = jsonData.title;
titleDiv.appendChild(title);
imageDiv.appendChild(titleDiv);
// create and add the download buttons
const videoUrls = jsonData.formats;
const buttonDiv = document.createElement("div");
buttonDiv.classList.add("down", "mdui-card-content", "mdui-center");
for (let i = 0; i < videoUrls.length; i++) {
const video = videoUrls[i];
const button = document.createElement("a");
button.innerHTML = `Download ${video.resolution}`;
button.href = video.url;
button.classList.add("mdui-btn", "mdui-btn-raised", "mdui-ripple", "mdui-color-theme-accent");
// set the flex property to align the buttons
if (i === 0) button.style.flex = "1 0 auto";
else if (i === 1) button.style.flex = "0 0 auto";
else button.style.flex = "1 0 auto";
// set the width of each button
button.style.width = "160px";
buttonDiv.appendChild(button);
}
// create container for image, title, and download buttons
const contentDiv = document.createElement("div");
contentDiv.classList.add("mdui-card-content");
contentDiv.style.display = "flex";
contentDiv.style.flexDirection = "column"; // set flex direction to column
contentDiv.appendChild(imageDiv);
// create div for title and buttons
const titleAndButtonsDiv = document.createElement("div");
titleAndButtonsDiv.style.display = "flex";
titleAndButtonsDiv.style.flexDirection = "column"; // set flex direction to column
titleAndButtonsDiv.style.alignItems = "center"; // center align items
// append the title and button containers to the new div
titleAndButtonsDiv.appendChild(titleDiv);
titleAndButtonsDiv.appendChild(buttonDiv);
// append the new div to the content container
contentDiv.appendChild(titleAndButtonsDiv);
// add the image, title, and button divs to the container
document.getElementById("container").appendChild(contentDiv);
// get resolution max url and createQRCode start
const resolutions = jsonData.formats.map(format => format.resolution);
const maxResolution = Math.max(...resolutions.map(resolution => parseInt(resolution.split("x")[0])));
const maxResolutionUrl = jsonData.formats.find(format => format.resolution.startsWith(`${maxResolution}x`)).url;
createQRCode(maxResolutionUrl);
// get resolution max url and createQRCode end
const thumbImg = document.querySelector('.thumb-img1');
thumbImg.style.display = 'none';
} catch (error) {
document.getElementById("error_message").style.display = "block";
document.getElementById("video_link").value = "";
document.getElementById("form_url").reset();
document.getElementById("error_message").style.color = "#058a05";
download_btn.innerText = "Downloaded";
download_btn.removeAttribute("disabled");
}
function createQRCode(url) {
const container = document.createElement("div");
container.classList.add("mdui-card-footer", "mdui-center", "mdui-m-t-2");
const p = document.createElement("p");
p.classList.add("qrcode-p", "mdui-typo-caption");
p.textContent = "扫描下面的QR码,直接下载到您的智能手机或平板电脑!";
container.appendChild(p);
const qrcodeContainer = document.createElement("div");
qrcodeContainer.classList.add("qrcode-div");
const qrcodeDiv = document.createElement("div");
qrcodeDiv.setAttribute("id", "qrcode");
qrcodeContainer.appendChild(qrcodeDiv);
container.appendChild(qrcodeContainer);
const script = document.createElement("script");
script.src = "/twitter/assets/js/qrcode.min.js";
script.onload = () => {
new QRCode(document.getElementById("qrcode"), {
text: url,
width: 120,
height: 120,
correctLevel : QRCode.CorrectLevel.L
});
}
container.appendChild(script);
// add the container to the body
document.getElementById("container").appendChild(container);
}
});
</script>
</body>
</html
|
1
2
3
4
5
6
| <body>
<div id="app">
</div>
</body>
|
加入 广告位置 在
直接加入下面代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| <style>
.loading-wrap {
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
}
.balls {
width: 4em;
display: flex;
flex-flow: row nowrap;
align-items: center;
justify-content: space-between;
}
.balls div {
width: 0.8em;
height: 0.8em;
border-radius: 50%;
background-color: #4b9e5f;
}
.balls div:nth-of-type(1) {
transform: translateX(-100%);
animation: left-swing 0.5s ease-in alternate infinite;
}
.balls div:nth-of-type(3) {
transform: translateX(-95%);
animation: right-swing 0.5s ease-out alternate infinite;
}
@keyframes left-swing {
50%,
100% {
transform: translateX(95%);
}
}
@keyframes right-swing {
50% {
transform: translateX(-95%);
}
100% {
transform: translateX(100%);
}
}
@media (prefers-color-scheme: dark) {
body {
background: #121212;
}
}
</style>
<div class="loading-wrap">
<div class="balls">
<div></div>
<div></div>
<div></div>
</div>
</div>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| ---- 自动广告start----
<script async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-2094041867720566" crossorigin="anonymous"></script>
---- 自动广告end----
---- 自适应-纵向 4268988277start ----
<script async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-2094041867720566"
crossorigin="anonymous"></script>
<!-- 自适应-纵向 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-2094041867720566"
data-ad-slot="4268988277"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
---- 自适应-纵向end ----
----文章内嵌广告-2start 8556922965----
<script async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-2094041867720566"
crossorigin="anonymous"></script>
<ins class="adsbygoogle"
style="display:block; text-align:center;"
data-ad-layout="in-article"
data-ad-format="fluid"
data-ad-client="ca-pub-2094041867720566"
data-ad-slot="8556922965"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
----文章内嵌广告-2end----
---- 横向-自适应-2start 5734344735----
<script async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-2094041867720566"
crossorigin="anonymous"></script>
<!-- 横向-自适应-2 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-2094041867720566"
data-ad-slot="5734344735"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
---- 横向-自适应-2 end ----
|
安装好libmaxminddb核心库 ,安装nginx ,以及ngx_http_geoip2_module模块
下载 GeoLite2-City.mmdb
GeoLite2-Country.mmdb ip库
具体可以看openai-chatgpt-web.zh-cn.md
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| ##################geoip2 start##################
geoip2 /usr/share/GeoIP/GeoLite2-Country.mmdb {
# 启用自动重新加载将使 nginx 以指定的时间间隔检查数据库的修改时间,如果发生更改则重新加载。
auto_reload 7d;
$geoip2_country_code country names en;
}
####ip api start####
geoip2 /usr/share/GeoIP/GeoLite2-City.mmdb {
# 中国IP访问都显示中文
$geoip2_data_country "default=中国" source=$remote_addr country names zh-CN; # 中国
$geoip2_data_country_code country iso_code; # CN
$geoip2_data_country_continent continent names zh-CN; # 亚洲
$geoip2_data_country_continent_code continent code; # AS
$geoip2_data_province_name subdivisions 0 names zh-CN; # 浙江省
$geoip2_data_province_isocode subdivisions 0 names iso_code; # "ZJ"
$geoip2_data_city city names zh-CN; # 杭州
$geoip2_data_city_longitude location longitude; # 120.161200
$geoip2_data_city_latitude location latitude; # 30.299400
$geoip2_data_city_time_zone location time_zone; # "Asia/Shanghai"
# 中国以外的访问都是显示英文
$geoip2_data_country_en "default=United States" source=$remote_addr country names en; # United States
$geoip2_data_country_code country iso_code; # US
$geoip2_data_country_continent_en continent names en; # North America
$geoip2_data_country_continent_code continent code; # NA
$geoip2_data_province_name_en subdivisions 0 names en; # ""
$geoip2_data_province_isocode subdivisions 0 names iso_code; # ""
$geoip2_data_city city names en; # 杭州
$geoip2_data_city_longitude location longitude; # 120.161200
$geoip2_data_city_latitude location latitude; # 30.299400
$geoip2_data_city_time_zone location time_zone; # "Asia/Shanghai"
}
map $geoip2_data_country_code $CN {
CN yes;
TW yes;
HK yes;
MO yes;
default no;
}
####ip api end####
####按国家 适配到对应的语言程序目录start ####
map $geoip2_data_country_code $country {
default en;
JP ja;
CN zh;
US en;
}
####按国家 适配到对应的语言程序目录end ####
##################geoip2 end ##################
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| location /twitter {
####按国家 适配到对应的语言程序目录start ####
#如果用户ip是日本的 浏览器地址栏显示https://save.test.com/twitter/ja 如果ip是中国的 浏览器地址栏显示https://save.test.com/twitter/zh 如果ip是美国的 浏览器地址栏显示https://save.test.com/twitter/en
#try_files $uri $uri/ /twitter/index.html;
rewrite ^/twitter$ /twitter/$country break;
rewrite ^/twitter/(en|ja|zh)/?$ /twitter/$1/index.html break;
root /home/wwwroot/xiaohuli/public;
index index.html;
}
####按国家 适配到对应的语言程序目录end####
location /twitter/language {
if ($arg_language = "en") {
return 302 /twitter/en/;
}
if ($arg_language = "ja") {
return 302 /twitter/ja/;
}
if ($arg_language = "zh") {
return 302 /twitter/zh/;
}
return 404;
}
|
这个nginx+ngx_http_geoip2 来实现显示访问者ip信息的 nginx api 。如果是查指定ip的信息 能否给个实现示例 比如html页面输入一个ip 就可以查询此ip的相关信息。比如ISP信息
在上面nginx配置中 1 怎么查询ISP相关信息 2怎么实现根据经纬度 显示在地图的具体位置点。
1 自动判断当前的页面是什么语言,比如当前是中文页面则显示是中文,下拉框可以选择english 日本语言 2下拉可以选择 english和日本语。如果点击english。则进入英文页面【也就是www.test.com/twitter/en/】 如果点击日本语 则进入日文页面【也就是www.test.com/twitter/ja/】
要实现自动判断当前页面语言并在下拉框中显示正确选项的功能,您可以使用JavaScript代码来检测当前页面URL中的语言代码,并将下拉框选项设置为相应的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| // 获取下拉框元素
var languageSelect = document.getElementById("language-select");
// 获取当前页面URL
var currentUrl = window.location.href;
// 如果当前页面URL中包含语言代码,则将下拉框选项设置为相应的值
if (currentUrl.match(/\/twitter\/([a-z]{2})\//)) {
var languageCode = RegExp.$1;
languageSelect.value = languageCode;
}
// 监听选择事件
languageSelect.addEventListener("change", function() {
// 获取选择的语言代码
var languageCode = this.value;
// 获取当前页面URL
var currentUrl = window.location.href;
// 如果当前页面URL中包含语言代码,则替换为新的语言代码
if (currentUrl.match(/\/twitter\/[a-z]{2}\//)) {
var newUrl = currentUrl.replace(/\/twitter\/[a-z]{2}\//, "/twitter/" + languageCode + "/");
window.location.href = newUrl;
} else {
// 否则,在当前页面URL后添加语言代码作为查询字符串参数
var newUrl = currentUrl + "?language=" + languageCode;
window.location.href = newUrl;
}
});
|
对应的html下拉框代码示例
1
2
3
4
5
| <select id="language-select">
<option value="zh">中文</option>
<option value="en">English</option>
<option value="ja">日本語</option>
</select>
|
当用户在下拉框中选择另一种语言时,您需要使用JavaScript将页面URL中的查询字符串参数"language"设置为相应的语言代码,并重新加载页面。然后,您需要在Nginx配置文件中添加重定向规则,将用户重定向到正确的语言版本
1
2
3
4
5
6
7
8
9
10
11
12
| location /twitter/language {
if ($arg_language = "en") {
return 302 /twitter/en/;
}
if ($arg_language = "ja") {
return 302 /twitter/ja/;
}
if ($arg_language = "zh") {
return 302 /twitter/zh/;
}
return 404;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| 检测机器人和获取用户浏览器指纹信息
<script>
function detectRobot() {
if (/HeadlessChrome/.test(navigator.userAgent) || // ua test
!window.chrome || // headless test
navigator.plugins.length === 0 || //plugins test
// languages test
!navigator.languages || navigator.languages.length === 0) {
return true;
}
const r = [];
const w = ['webdriver', '__driver_evaluate', '__webdriver_evaluate',
' __selenium_evaluate', '__fxdriver_evaluate', '__driver_unwrapped',
'__webdriver_unwrapped', '__selenium_unwrapped', '__fxdriver_unwrapped',
'_Selenium_IDE_Recorder', '_selenium', 'calledSelenium',
'_WEBDRIVER_ELEM_CACHE', 'ChromeDriverw', 'driver-evaluate',
'webdriver-evaluate', 'selenium-evaluate', 'webdriverCommand', 'webdriver-evaluate-response',
'__webdriverFunc', '__webdriver_script_fn', '__$webdriverAsyncExecutor', '__lastWatirAlert',
'__lastWatirConfirm', '__lastWatirPrompt', '$chrome_asyncScriptInfo', '$cdc_asdjflasutopfhvcZLmcfl_',
'_phantom', '_phantomas',
];
w.forEach((t) => {
if (!!window[t] || !!window.document.documentElement.getAttribute(t) || !!navigator[t]) {
r.push(t);
}
});
return r.length > 0;
}
Fingerprint2.getV18({}, function (result, components) {
var d = 0;
if (detectRobot()) {
d = 1;
}
$.post('/fingerprint.php?r=https%3A%2F%2Fwww.ipip.net%2F', {hash:result, d:d, components:components}, function(){})
});
</script>
|
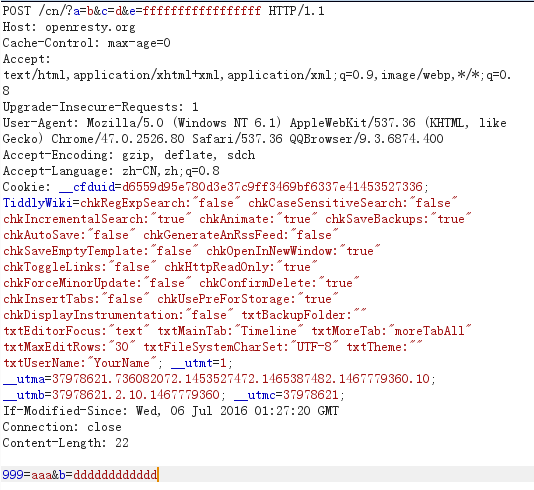
– request: “GET /api-hot HTTP/2.0”, host: “test.com”, referrer: “https://test.com/hot/" 怎么允许 满足这3>个条件的 才继续其它逻辑
不能直接访问 https://save.2urs.com/download 控制
/usr/local/nginx/conf/lua/twitter.lua 添加
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| -- request: "GET /api-hot HTTP/2.0", host: "test.com", referrer: "https://test.com/hot/" 怎么允许 满足这3>个条件的 才继续其它逻辑
-- request: "POST /download HTTP/2.0", host: "save.2urs.com", referrer: "https://save.2urs.com/twitter/"
ngx.log(ngx.INFO, "request referer: ", ngx.var.http_referer)
local client_ip = ngx.var.remote_addr
ngx.log(ngx.INFO, "client_ip ", ngx.var.remote_addr)
if ngx.var.request_method ~= "POST" then
ngx.exit(ngx.HTTP_BAD_REQUEST)
end
if ngx.var.host ~= "save.2urs.com" then
ngx.exit(ngx.HTTP_FORBIDDEN)
end
-- if not string.match(ngx.var.http_referer, "^https://save%.2urs%.com/twitter/.+/") then
if not string.match(ngx.var.http_referer, "^https://save%.2urs%.com/twitter/") then
ngx.exit(ngx.HTTP_FORBIDDEN)
end
-- 访问频率处理
|
重启nginx 生效
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| curl 'https://save.2urs.com/download' -H 'authority: save.2urs.com' -H 'content-type: application/json' -H 'origin: https://save.2urs.com' -H 'referer: https://save.2urs.com/twitter/' -H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.68' --data-raw '{"video_link":"https://twitter.com/i/status/1580927207987257344"}'
必须三要素【 -H 'referer: https://save.2urs.com/twitter/' -H 'origin: https://save.2urs.com' 】 有才通过: linux下通过
{
"formats": [
{
"resolution": "320x426",
"url": "https://video.twimg.com/ext_tw_video/1580927143961165824/pu/vid/320x426/OUQY29w6feHHQtZ3.mp4?tag=12"
},
{
"resolution": "720x960",
"url": "https://video.twimg.com/ext_tw_video/1580927143961165824/pu/vid/720x960/gjC0nXAeQE15l9Yb.mp4?tag=12"
},
{
"resolution": "480x640",
"url": "https://video.twimg.com/ext_tw_video/1580927143961165824/pu/vid/480x640/HzG1sKpaop-89nTu.mp4?tag=12"
}
],
"thumb": "https://pbs.twimg.com/ext_tw_video_thumb/1580927143961165824/pu/img/NxAVVJ86nF5NCmlW.jpg",
"title": "i_1580927207987257344"
}
---
curl 'https://save.2urs.com/download' -H 'content-type: application/json' -H 'referer: https://save.2urs.com/twitter/' -H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.68' --data-raw '{"video_link":"https://twitter.com/i/status/1580927207987257344"}'
去掉 -H 'origin: https://save.2urs.com' 请求404。
curl 'https://save.2urs.com/download' -H 'content-type: application/json' -H 'origin: https://save.2urs.com' -H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.68' --data-raw '{"video_link":"https://twitter.com/i/status/1580927207987257344"}'
如果去掉 -H 'referer: 也会报错 404。
curl 'https://save.2urs.com/download' -H --user-agent "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" -H "Host: save.2urs.com" -H "Referer: https://save.2urs.com/twitter/" -X POST -H "Content-Type: application/json" -d '{"video_link": "https://twitter.com/i/status/1580927207987257344"}'
请求 报404,虽然有 -H "Host: save.2urs.com"
curl 'https://save.2urs.com/download' -H --user-agent "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" -H 'origin: https://save.2urs.com' -H "Referer: https://save.2urs.com/twitter/" -X GET -H "Content-Type: application/json" -d '{"video_link": "https://twitter.com/i/status/1580927207987257344"}'
|
不能直接访问
查询自己的IP地址 https://save.2urs.com/ip/
request: “GET /api-hot HTTP/2.0”, host: “test.com”, 怎么允许 满足这2>个条件的 才继续其它逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
-- request: "GET /api-hot HTTP/2.0", host: "test.com", 怎么允许 满足这2>个条件的 才继续其它逻辑
-- request: "POST /download HTTP/2.0", host: "save.2urs.com",
ngx.log(ngx.INFO, "request referer: ", ngx.var.http_referer)
local client_ip = ngx.var.remote_addr
ngx.log(ngx.INFO, "client_ip ", ngx.var.remote_addr)
if ngx.var.request_method ~= "GET" then
ngx.exit(ngx.HTTP_BAD_REQUEST)
end
if ngx.var.host ~= "save.2urs.com" then
ngx.exit(ngx.HTTP_FORBIDDEN)
end
-- 访问频率处理
|
访问控制 https://2urs.com/api-hot/ https://save.2urs.com/api/ip https://save.2urs.com/ip
都做了 request: “GET /api-hot HTTP/2.0”, host: “test.com”, referrer: “https://test.com/hot/" ip和api/ip 没有做 referrer: “https://test.com/hot/"
1
| curl 'https://save.2urs.com/download' -H 'authority: save.2urs.com' -H 'content-type: application/json' -H 'origin: https://save.2urs.com' -H 'referer: https://save.2urs.com/twitter/' -H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.68' --data-raw '{"video_link":"https://twitter.com/i/status/1580927207987257344"}'
|
通过
op-sec-team/releases-openstar-Enterprise: releases-openstar-Enterprise (github.com)该版本是基于开源版 openstar 开发的企业版。目前完全免费!!!
关于功能、界面有好的建议可以反馈给我们,谢谢~
QQ号:2194788831QQ群:331447905 入群领取 web 管理后台的包
Cc : cc 攻击
Sql : sql 注入攻击
Xss : xss 攻击
Brute_force : 暴力破解攻击
Webshell : 网站后门攻击
Danger_path : 危险路径攻击
Danger_keyword : 危险关键字攻击
Scan : 扫描攻击
Struts2 : struts2命令执行攻击
Csrf : csrf 跨站请求攻击
Stealing_link : 防盗链攻击
Black_ip : ip黑名单
Anti_reply : 重放攻击
Back_door : 后门攻击
https://github.com/op-sec-team/releases-openstar-Enterprise
curl –user-agent “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36” -X POST -H “Content-Type: application/json” –data-raw ‘{“video_link”: “https://twitter.com/azi1024/status/1447067030008385539"}' https://chat.f2bb.com/download 不通过
OpenResty简介
OpenResty是将Nginx与 Lua粘合的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块等。用于方便地搭建高并发、扩展性极高的动态Web 应用、Web 服务和动态网关。从听说到使用了OpenResty之后,感觉这是瑞士军刀,应用实在太广泛。
我们公司目前没有专门的安全工程师,安全的一些工作就落到我们运维工程师头上,遇到安全问题就找到我们身上了,因此我想做一个web应用防火墙,让开发人员不用考虑安全问题只关心业务开发;因此就考虑开发WAF来解决现在遇到的问题。
WAF就是web应用防火墙,是对网站进行安全防护的。一个http/https的请求,包含数据: url、get参数、post参数、协议版本/method/host/agent/cookie等http请求头。 如下图所示:
 而WAF就可以对请求中的参数、访问频率进行安全检查(正则匹配为主),触发危险操作的请求,就进行拦截、记录操作。 当然WAF解决是还是web安全1.0和2.0的问题。对应业务逻辑本身WAF目前是不能通用的进行防护的。
而WAF就可以对请求中的参数、访问频率进行安全检查(正则匹配为主),触发危险操作的请求,就进行拦截、记录操作。 当然WAF解决是还是web安全1.0和2.0的问题。对应业务逻辑本身WAF目前是不能通用的进行防护的。
WEB****安全1.0
在1.0时代下,攻击是通过服务器漏洞(IIS6溢出等)、WEB应用漏洞(SQL注入、文件上传、命令执行、文件包含等)属于服务器类的攻击,该类型漏洞虽然经历了这么多年,很遗憾,此类漏洞还是存在,并且重复在犯相同的错误。
WEB****安全2.0
随着社交网络的兴起,原来不被重视的XSS、CSRF等漏洞逐渐进入人们的视野,那么在2.0时代,漏洞利用的思想将更重要,发挥你的想象,可以有太多可能。
WEB****安全3.0
同开发设计模式类似(界面、业务逻辑、数据),3.0将关注应用本身的业务逻辑和数据安全,如密码修改绕过、二级密码绕过、支付类漏洞、刷钱等类型的漏洞,故注重的是产品本身的业务安全、数据安全。
我设计的WAF过滤流程,只是根据我的理解来设计他的处理流程,不一定是最合理的,但是解决了我们现在遇到的问题。整个设计是在Nginx执行的相应阶段完成一些相应的动作,如在init阶段完成数据初始化、rewrite阶段暂时没用,预计未来跳转使用(如验证码、set cookie等)、access阶段实施拦截防护(大多数过滤在这完成)、body_filter阶段进行响应内容的替换(如非法关键词替换)。
在nginx初始化阶段,我们可以初始化如ip黑白名单;初始化ip计数器;此处我们用到了几个共享字典来存储这些数据(如1MB大约存ip数量1000个)。
lua_shared_dicttoken_list 20m; # token 存放
lua_shared_dictcount_dict 5m; # 用于拦截计数数据的保存
lua_shared_dictconfig_dict 5m; # 保存config中部分配置
lua_shared_dictip_dict 30m; # 用于记录黑、白名单ip
lua_shared_dictlimit_ip_dict 100m; # 用于 IP 访问计数统计
在初始化阶段,会读取全局配置文件config.json和规则配置文件xxx_Mod.json,存放到config_dict中;其次,读取配置的ip黑白名单存放到ip_dict;然后定义一些公共函数如sayHtml,sayFile,sayLua等等。
我们主要的拦截就在该阶段操作的,整体的防护分为13个步骤进行分层防护的,如下图所示。

0、realIpFrom_Mod==>获取用户真实IP:获取用户真实ip 在一些网络场景下,用户真实ip在http头中,所以我们先要把真实ip取出来;
1、ip_Mod==>ip黑白名单的过滤(黑白名单):ip白名单后续的规则都跳过了,请求继续走;ip黑名单,就是在应用层进行拦截,请求到这里就停了,不会到后端了;
2、host_method_Mod==>host&method过滤(白名单):这里就是域名准入,和method的准入了,可以配置允许的host,允许的method;
3、app_Mod==>自定义过滤动作:这里提供的几个动作是:返回字符串、返回文件内容、动态执行lua脚本、记录log、匹配白名单(ip,args参数);基本匹配的是:host、url在后续的场景中我在举一些例子;
4、referer_Mod==>referer规则过滤(白名单):一些图片资源的防盗链,站外的CSRF就是通过referer来过滤的;
5、url_Mod==>url过滤(黑、白名单):
“.(svn|git|htaccess|bash_history)” — 敏感文件、目录、备份文件黑名单拦截;
“.(css|js|flv|swf|woff|txt)$” – 静态资源文件白名单,这样后续的过滤规则都会跳过,减少总的匹配次数,提高效率;以及访问频率统计时,去掉这些静态文件的统计;
6、header_Mod==>header过滤(黑名单):一些扫描器,爆破工具,黑客工具有时在http头中会有一些标记,这里我们就可以过掉;
{
“state”: “on”,
“url”:[”*”,””],
“hostname”:["*",""],
“header”:[“Acunetix_Aspect”,"*",""]
},
– 扫描器 wvs 的标记
{
“state”: “on”,
“url”:["*",""],
“hostname”:["*",""],
“header”: [“X_Scan_Memo”,"*",""]
}
– 扫描器 Scan 的标记
7、useragent_Mod==>user-agent过滤(黑名单):这里是过滤一些常见黑客工具,压测工具等;
havij|sqlmap|nmap|HTTrack…
8、cookie_Mod==>cookie过滤(黑名单):这里是对cookie进行SQL注入、XSS、遍历、敏感文件读取等一些规则的过滤;
9、args_Mod==>GET参数过滤(黑名单):这里是对args参数进行SQL注入、XSS、遍历、敏感文件读取等一些规则的过滤;
if config_is_on(“args_Mod”) then
local args_mod =getDict_Config(“args_Mod”)
local args =ngx.unescape_uri(ngx.var.query_string)
if args ~= "" then
for i,v in ipairs(args_mod) do
if v.state == “on” then
if remath(host,v.hostname[1],v.hostname[2])then
if remath(args,v.args[1],v.args[2]) then
Set_count_dict(“args_deny count”)
action_deny()
break
end
end
end
end
end
end
看一下代码,对于参数污染这种绕WAF的方式,还有url编码绕过方式也是无法绕过的,代码中首先进行了转码、在取整个args,而不是一个一个取在拼接上;
10、post_Mod==>post参数过滤(黑名单):这里是对post参数进行SQL注入、XSS、遍历、敏感文件读取等一些规则的过滤;
localfunction get_postargs()
ngx.req.read_body()
local data = ngx.req.get_body_data() –ngx.req.get_post_args()
if not data then
local datafile =ngx.req.get_body_file()
if datafile then
local fh, err = io.open(datafile,“r”)
if fh then
fh:seek(“set”)
data = fh:read("*a")
fh:close()
end
end
end
return ngx.unescape_uri(data)
end
if config_is_on(“post_Mod”) and method == “POST” then
–debug(“post_Mod is on”)
local post_mod =getDict_Config(“post_Mod”)
local postargs = get_postargs()
if postargs ~= "" then
for i,v in ipairs(post_mod) do
if v.state == “on” then
–debug(i.." post_modstate is on")
if remath(host,v.hostname[1],v.hostname[2]) then
if remath(postargs,v.post[1],v.post[2]) then
Set_count_dict(“post_deny count”)
debug(“post_Mod :”..postargs..“No : “..i,“post_deny”,ip)
action_deny()
break
end
end
end
end
end
end
代码中是取整个body的,而不是通过ngx.req.get_post_args(),且最后也转码了,所以通过参数污染、url转码是不能绕过的;
11、network_Mod==>访问频率过滤(频率黑名单):先看一个配置:
– 单个URL的频率限制
– 因为一个网站一般情况下容易被CC的点就那么几个
{
“state”: “on”,
“network”:{“maxReqs”:10,“pTime”:10,“blackTime”:600},
“hostname”:[[“101.200.122.200”,“127.0.0.1”],“table”],
“url”:["/api/time”,”"]
}
– 限制整个网站的(范围大的一定要放下面)
{
“state”: “on”,
“network”:{“maxReqs”:30,“pTime”:10,“blackTime”:600},
“hostname”:[[“101.200.122.200”,“127.0.0.1”],“table”],
“url”:["*",""]
}
– 限制ip的不区分host和url
{
“state”: “on”,
“network”:{“maxReqs”:100,“pTime”:10,“blackTime”:600},
“hostname”:["*",""],
“url”:["*",""]
}
相对来说比较灵活,可以配置某个url的ip访问频率,以及在前面提到过,一些静态文件css/js/img文件是可以不计数的。
9.0.3 body_filter 阶段
12、replace_Mod==>应答内容的替换:这里就是对返回内容的动态替换的功能,比如替换一些非法关键词等。
1、简单的正则添加:如我们需要过滤以.sql结尾的请求URL,那么就在url_Mod中设置
{
“state”: “on”,
“hostname”: [
“*”,
""
],
“url”: [
“\.(bak|inc|old|mdb|sql|backup|java|class)$”,
“jio”
],
“action”: “deny”
}
2、我们需要设置管理后台仅允许部分ip可以访问,那么就在app_Mod中设置
{
“state”: “on”,
“action”:[“allow”],
“allow”:[“ip”,[“106.37.236.170”,“1.1.1.1”],“table”],
“hostname”:[[“101.200.122.200”,“127.0.0.1”],“table”],
“url”:["/api/.*",“jio”]
}
看着配置也比较容易理解,host是101.200.122.200或者127.0.0.1的,访问的目录是/api/.*的,仅允许allow中的2个IP。
3、CC攻击防护
攻击类型
1)、行为(GET、POST等):目前主要还是这两种method攻击为主,其他的基本没有,因为比较互联网上的web应用也都是这两种居多;
2)、被攻击的点(前端的纬度) a: 用户可直接访问的URL(搜索、重CPU、IO、数据库的点);b:嵌入的URL(验证码、ajax接口等);c:面向非浏览器的接口(一些API、WEBservice等);d:基于特定web服务、语言等的特定攻击(慢速攻击、PHP-dos等)。
防护方法
1)网络层:通过访问ip的频率、统计等使用阀值的方式进行频率和次数的限制,黑名单方式;
2)网络层+应用层:在后来的互联网网络下,有了CDN的加入,现在增加的网络层的防护需要扩展,那么统计的IP将是在HTTP头中的IP,仍然使用频率、次数、黑名单的方式操作。
3)应用层:TAG验证、SET COOKIE、URL跳转、JS跳转、验证码、页面嵌套、强制静态缓存等;防护是需要根据攻击点进行分别防护的,如攻击的是嵌入的url,我们就不能使用JS跳转、302验证码等这样的方法;在多次的CC防护实战中,如使用url跳转、setcookie;在新型的CC攻击下,这些防护都已经失效了。浏览器是可以执行JS和flash的,这里我分享一些基于JS的防护算法,flash需要自己去写(比js复杂一些),可以实现flash应用层的安全防护和防页面抓取(开动你的大脑吧);
4)客户端防护:使用JS进行前端的防护(浏览器识别、鼠标轨迹判断、url有规则添加尾巴(args参数)、随机延迟、鼠标键盘事件获取等)其实这里非常复杂,如浏览器的识别 ie 支持 !-[1,]这个特殊JS,一些浏览器有自定义标签等等;
5)服务端防护:url添加的尾巴(args参数)是服务器动态生成的token,而不是使用静态的正则去匹配其合法性;
6)特定攻击:该类特定攻击,可以通过特征快速匹配出来(慢速攻击、PHP5.3的http头攻击)。
目前已经有了一些应用层的防护都是基于js的(还得自己写js),后续有时间会把验证码等加上,这个很实用。
误报肯定是有的,使用时需要根据自己的业务进行调整。
提供了相应的http接口来增删相应的规则;方便规则的维护。
更多案例和配置示例请参考https://github.com/starjun/openstar。
由于本应用时为了解决当前公司的存在的问题,代码质量、代码实现可能存在不到位的地方,多多探讨。感谢春哥、OpenResty社区、loveshell。
抖音
帶標籤黑絲襪的影片 (tktube.com)
https://jp.pornhub.com/view_video.php?viewkey=ph612a1d50ecbf0
最新啪啪私拍 扶着楼梯翘美臀后入无套抽插丝滑阴道 sese277.info)
【女性私密SPA护理按摩】 https://x99av.com/video/38030 https://avqq.com/videos/41046/spa86.html 女性私密养生会所《推油少年》 videodown插件下载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| <script>
window.addEventListener("load", () => {
let alertTXT = "We detect that you may be using AdBlock or Adblock Plus.\nYou can set special rules or whitelist DLPanda so that we can develop better and continue to provide you with a quality service.\n\n我们检测到您可能使用了 AdBlock 或 Adblock Plus.\n您可以设定特殊规则或将DLPanda加入白名单,以便我们更好发展下去,为您持续提供优质服务。";
let adblockEnabled = false;
let xhr = new XMLHttpRequest();
xhr.open('GET', 'https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js', false);
xhr.onerror = function() {
adblockEnabled = true;
console.log('The request was blocked by the client');
};
try {
xhr.send();
}
catch (e) {
console.log(e);
alert(alertTXT);
return;
}
if (xhr.status === 404 || xhr.responseText.indexOf('blocked') !== -1) {
adblockEnabled = true;
}
if(adblockEnabled) {
alert(alertTXT);
}
});
</script>
|
https://twitter.com/azi1024/status/1447067030008385539
用python或php实现下面需求。请仔细看,认真看需求。
需求1:在页面1 输入https://twitter.com/i/status/1595954302438166529 按下载按钮
需求2:进入下载页面, 显示对应视频相应分辨率的下载按钮。比如这个视频加入有7201280,480852,320568的分辨率 ,则按钮1显示: 下载7201280 按钮2显示,按钮2显示:下载480852, 按钮3显示: 下载320568。点击相应的按钮则 进入新页面打开视频。 比如点击下载7201280 进入新页面 url是 https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/720x1280/p6gZ3sv9Hx2JeRoL.mp4?tag=12 这样视频播放。右击点击下载7201280 选另存为也会保存视频。
需求3:按钮1,按钮2,按钮3 需要并排显示 。并在 这几个按钮的并排区域前面显示一个这个url视频的标题信息,
需求4:这个url视频的标题信息的前面, 引用mp4,以方便在页面显示视频,点击视频时能播放。从页面布局来说 引用视频画面,url标题信息,相关下载的按钮, 这三部分视觉看起来是 平行的。看起来好像都在一个区块里一样,显得很平整。假如叫做主要区块。
需求5:在主要区块下面显示 ,显示最大分辨率的下载地址的二维码 QR码。也就是说把上面url得到的视频最大分辨率的下载地址 比如是https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/720x1280/p6gZ3sv9Hx2JeRoL.mp4?tag=12 变成 QR二维码,这样手机扫描图片后可以直接下载。
前端 www.xxx.com/twitter
后端flask 服务地址是 127.0.0.1:8010
后端用nginx 做了跳转,配置如下
1
2
3
| location /download {
proxy_pass http://127.0.0.1:8010;
}
|
这个用curl怎么模拟
为什么打开www.xxx.com/twitter 输入https://twitter.com/i/status/1595954302438166529 点击Download 无反应
1
2
3
4
5
6
| curl --user-agent "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" -X POST -H "Content-Type: application/json" -d '{"video_link": "https://twitter.com/i/status/1595954302438166529"}' http://2urs.com/download 不可以
curl --user-agent "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" -X POST -H "Content-Type: application/json" -d '{"video_link": "https://twitter.com/azi1024/status/1447067030008385539"}' https://chat.f2bb.com/download 可以 , 网页访问 https://chat.f2bb.com/twitter
http://2urs.com/download?video_link=https://twitter.com/azi1024/status/1447067030008385539 不可以
|
这是一个具体的需求,需要在页面上实现视频下载和二维码生成功能。下面是用 Python 和 PHP 实现这个需求的示例代码。
用 Python 实现:
需求1:使用 Flask 框架建立一个简单的 web 应用程序,在页面上输入 URL,点击下载按钮。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| from flask import Flask, render_template, request
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/download', methods=['POST'])
def download():
url = request.form['url']
# 在这里处理 URL,获取分辨率信息
resolutions = get_resolutions(url)
# 渲染下载页面,显示分辨率按钮
return render_template('download.html', resolutions=resolutions)
if __name__ == '__main__':
app.run(debug=True)
|
需求2:在下载页面上显示分辨率按钮,点击按钮进入新页面播放视频。
download.html
1
2
3
4
5
| <div>
{% for resolution in resolutions %}
<a href="{{ resolution.url }}" target="_blank">下载 {{ resolution.width }}x{{ resolution.height }}</a>
{% endfor %}
</div>
|
需求3:在分辨率按钮区域前面显示视频标题信息。
download.html
1
2
3
4
5
6
| <h1>{{ title }}</h1>
<div>
{% for resolution in resolutions %}
<a href="{{ resolution.url }}" target="_blank">下载 {{ resolution.width }}x{{ resolution.height }}</a>
{% endfor %}
</div>
|
需求4:在视频标题信息前面引用视
实现这些需求需要使用到 Python 或 PHP 的网络爬虫库(如 BeautifulSoup)来爬取网页信息和解析HTML,还需要使用到 Python 或 PHP 的 HTTP 库(如 requests)来请求网页。
具体实现步骤如下:
使用网络爬虫库爬取输入的URL,获取页面信息。
解析页面信息,获取视频标题和不同分辨率的视频地址。
根据不同分辨率的视频地址生成对应的下载按钮。
显示视频标题、视频画面、相关下载按钮。
在主要区块下面显示最大分辨率的下载地址的二维码。
需要注意的是,在实现这些需求时需要遵循网站的使用条款和隐私政策,并且需要考虑到网站防爬虫措施。
— 视频下载二维码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| <div class="text-center">
<p class="qrcode-p">扫描下面的QR码,直接下载到您的智能手机或平板电脑!</p>
</div>
</div>
<div class="col-md-4 col-centered qrcode">
<div id="qrcode"></div>
<script src="/public/assets/js/qrcode.min.js"></script> <script type="text/javascript">
new QRCode(document.getElementById("qrcode"),{
text: "https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/720x1280/p6gZ3sv9Hx2JeRoL.mp4?tag=12",
width: 120,
height: 120,
correctLevel : QRCode.CorrectLevel.L
});
</script>
</div>
---
.card {
background: #fff;
border: 1px solid #eee;
padding: 5px;
}
<div class="card">
<div class="row">
<div class="col-md-3">
<a href="#myModalVideo" data-toggle="modal" class="card-aside-column img-video" style="height:79px;background: #c7c7c7;background-size:cover;background-image: url(http://pbs.twimg.com/ext_tw_video_thumb/1595954260465704960/pu/img/g5hHPs-oOX2Vzp18.jpg)">
<span class="btn-play-video video-btn"><i class="glyphicon glyphicon-play"></i></span>
<p class="time-video" id="time">00:12</p> </a>
</div>
<div class="col-md-5 no-padd">
<div class="card-block">
<h5><a href="https://twitter.com/i/status/1595954302438166529" target="_blank">杭州小玉居家服务系</a></h5> <p class="card-text">#杭州 #杭州双飞 #杭州同城 #杭州丝足 #杭州spa #杭州按摩 #杭州楼凤 #杭州约啪 #杭州修车 #杭州线下 #杭州兼职 https://t.co/sy3kiCxcpO</p> </div>
</div>
<div class="col-md-4 btns-download">
<p class="downloadLink" id="720x1280link">
<a href="https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/720x1280/p6gZ3sv9Hx2JeRoL.mp4?tag=12" target="_blank" class="btn btn-download">下载 720x1280</a>
</p>
<p class="downloadLink" id="480x852link">
<a href="https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/480x852/dGS1AqHlSBbBGY10.mp4?tag=12" target="_blank" class="btn btn-download">下载 480x852</a>
</p>
<p class="downloadLink" id="320x568link">
<a href="https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/320x568/7uB0nnxyhIQwVJca.mp4?tag=12" target="_blank" class="btn btn-download">下载 320x568</a>
</p>
</div>
</div>
</div>
|
从上面中断的这行 需求4:在视频标题信息前面引用视 这里继续说剩下的。
好的,继续说,需求4:在视频标题信息前面引用视频的发布者和发布时间。这样可以让用户更好地了解视频的来源和发布时间,并且可以帮助用户更好地筛选和查找视频。
从上面中断的这行 需求4:在视频标题信息前面引用视 这里继续写代码
您可以使用 JavaScript 来实现这个需求。
1
2
3
4
5
6
7
8
| // 获取所有视频标题元素
let videoTitles = document.querySelectorAll('.video-title');
// 遍历每个元素
videoTitles.forEach(function(title) {
// 在标题前面添加引用
title.innerHTML = '视频:' + title.innerHTML;
});
|
这段代码首先通过 document.querySelectorAll(’.video-title’) 来获取所有具有类名为 video-title 的元素,然后遍历每个元素,使用 title.innerHTML = ‘视频:’ + title.innerHTML; 来在标题前面添加引用"视频:"。
请注意,如果您使用的是 jQuery,可以使用以下代码来实现相同的功能:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| $('.video-title').prepend('视频:');
两种方式都能够实现在视频标题信息前面引用视频的需求。
# 后端
@app.route('/download', methods=['POST'])
def download():
video_link = request.json['video_link']
# 解析视频地址
video_url = parse_video_url(video_link)
# 获取下载地址
download_url = get_download_url(video_url)
# 返回结果
return jsonify({'download_url': download_url})
def parse_video_url(video_link):
# 使用正则表达式或其他方式解析视频地址
pass
def get_download_url(video_url):
# 使用第三方库或其他方式获取下载地址
pass
# 前端
async function downloadVideo() {
const video_link = document.getElementById('video_link').value;
const data = {video_link: video_link};
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(data)
};
const response = await fetch('http://localhost:8010/download', options);
const result = await response.json();
console.log(result);
}
document.getElementById('download_btn').addEventListener('click', downloadVideo);
|
—old
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| <script>
var video_link = document.getElementById("video_link").value;
fetch("https://www.2urs.com/download", {
method: "POST",
body: JSON.stringify({ "video_link": video_link }),
headers: { "Content-Type": "application/json" },
})
.then( response => {
try{
response.json()
}catch(e){
throw new Error('Unexpected token E, "Error occurred" is not valid JSON')
}
})
.then(data) => {
document.getElementById("video_title").innerHTML = data.title;
var download_links = "";
for (var resolution in data.links) {
download_links += `<a href="${data.links[resolution]}" download>Download ${resolution}</a>`;
}
document.getElementById("download_links").innerHTML = download_links;
var qr_code = new QRCode(document.getElementById("qr_code"), {
text: data.links.high,
width: 128,
height: 128,
colorDark: "#000000",
colorLight: "#ffffff",
correctLevel: QRCode.CorrectLevel.H,
});
});
}
</script>
|
我意思提示的文字为 浅绿色字体这个能定义吗,
有问题,输入url1 点download后,有响应 ,输入url2,点download后,就无响应。如果是错误的url也不报错输出之前的那种提示。
https://twitter.com/i/status/1364509839179673603 视频以删除测试无响应测试
https://twitter.com/i/status/1457373248874692608 404
https://www.getfvid.com/zh/twitter
https://twitter.com/NNwcNW63i76sXrT/status/1595954302438166529 ok
https://twitter.com/i/status/1595954302438166529 ok
https://twdown.app/ https://github.com/egoist/download-twitter-video
https://twitter.com/i/status/1447067030008385539 ok
视频下载链接
“https://video.twimg.com/ext_tw_video/1447066955362361345/pu/vid/720x1280/NygqUru4Tn59uYl6.mp4?tag=12"
需求是:按钮变成上 中 下 这样竖着排 然后这部分按钮区块跟图片 、titl文字、 横着排 ,达到左边图片 中间 title文字 右边是按钮区块
下面是 js生成的 样式。我不知道哪里有问题?需要改从什么样的 才能达到要求
图片
1
2
| title <div style="display: flex; align-items: center;">
按钮区块 <div style="display: flex; align-items: center; justify-content: flex-end;"><button>Download 320x568</button><button>Download 480x852</button><button>Download 720x1280</button></div>
|
yt-dlp获取twitter页面视频地址
./yt-dlp --dump-json --no-check-certificates --no-warnings https://twitter.com/i/status/1447067030008385539
你说js那段代码是一个API 处理程序,那怎么使用你这个这个python版的呢? flask后端 怎么传给他url,以及他响应后怎么 传给 flask。
1
2
3
4
5
6
7
| result = run(["./yt-dlp", "https://twitter.com/i/status/1447067030008385539", "--dump-json", "--no-check-certificates", "--no-warnings"], stdout=PIPE, stderr=PIPE)
videos = [json.loads(line)['https://twitter.com/i/status/1447067030008385539'] for line in result.stdout.decode().split('\n') if line]
print (jsonify({'data': {'videos': videos}}))
https://twitter.com/Hong_Doo_JV2/status/1606904304014884864
curl -X GET http://localhost:8010/api/process?video_link=https://twitter.com/i/status/1447067030008385539
curl -X GET http://localhost:8010/api/process?video_link=https://xxx.com/xxx
|
那不是要启动2个flask,你之前不是有个app.route download的flask吗 可以放在一起吗?
flask中@app.route("/download"中的download函数 执行函数gv, 并把video_link传给gv ,gv 调用/api/process 把video_link传给/api/process, /api/process把处理结果 返回直到html 这样写合理吗?影响效率吗 ```
可以这样写的,但是如果视频链接数量很多或者视频处理时间很长,这样写可能会影响用户体验,因为用户需要等待所有视频链接都处理完成后才能得到结果。为了提高用户体验,可以考虑使用异步处理,比如使用 Celery 或者 asyncio 来处理视频。
前 后端 打通
1
2
3
4
5
6
7
8
| curl --user-agent "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" -X POST -H "Content-Type: application/json" -d '{"video_link": "https://twitter.com/i/status/1595954302438166529"}' https://www.2urs.com/download
curl --user-agent "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" -X POST -H "Content-Type: application/json" -d '{"video_link": "https://twitter.com/i/status/1595954302438166529"}' https://www.2urs.com/download
curl --user-agent "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" -X POST -H "Content-Type: application/json" -d "{"video_link": "https://twitter.com/i/status/1595954302438166529"}" https://www.2urs.com/download
接口 curl -X GET http://localhost:8010/api/process?video_link={https://twitter.com/i/status/1447067030008385539}
|
现在点download按钮返回的是json {"data": {"videos": [ "https://tadxdd3.com/tdd/a " ]..... }}
如何做到点击download按钮,打开新页面
显示对应视频相应分辨率的下载按钮。比如这个json含有3个视频 假如有7201280,480852,320568的分辨率 ,则按钮1显示: 下载7201280 按钮2显示,按钮2显示:下载480852, 按钮3显示: 下载320568。点击相应的按钮则 进入新页面打开视频。 比如点击下载7201280 进入新页面 url是 https://xxx.com/test/15/pu/vid/720x1280/testl6.mp4?tag=12 这样视频播放。右击点击下载7201280 选另存为也会保存视频。
需求3:按钮1,按钮2,按钮3 需要并排显示 。并在 这几个按钮的并排区域前面显示一个这个url视频的标题信息。【假如返回的json数据有title】
需求4:这个url视频的标题信息的前面, 引用mp4,以方便在页面显示视频,点击视频时能播放。从页面布局来说 引用视频画面,url标题信息,相关下载的按钮, 这三部分视觉看起来是 平行的。看起来好像都在一个区块里一样,显得很平整。假如叫做主要区块。
需求5:在主要区块下面显示 ,显示最大分辨率的下载地址的二维码 QR码。也就是说把上面url得到的视频最大分辨率的下载地址 比如是https://xxx.com/test/15/pu/vid/720x1280/testl6.mp4?tag=12 变成 QR二维码,这样手机扫描图片后可以直接下载。
将命令的标准输出分割成行,并将每行映射为一个 JSON 对象,并返回一个包含所有视频 URL 的对象给客户端.
这两行代码是在解析check_output()函数返回的结果,第一行是将结果中每一行内容转化为json格式,再取出里面的’url’值,放入列表中。
webpage_url
title 行 截取前30个字符串
formats 行 下很多行,取下面的 “protocol” 为"https"的url 和resolution
thumbnails行下的 “id"为 small 的url,
并把上面映射为json,返回
我认为fetch请求中调用/download接口就可以了,json返回足够的数据 比如所有视频url及分辨率,标题title 。
前端js 处理 ,按要求展示。
videos = [json.loads(line)[‘url’] for line in result.stdout.decode().split(’\n’) if line] 之前你是将结果中每一行内容转化为json格式,再取出里面的’url’值,
下面数据是bin/xxx的输出
1
2
3
4
5
6
| {"id":"144706695533335","title":"\u6296\u97f3\u5feb\u624b\u4e3b\u64ad\u798f","formats":[{"format_id":"hls-632","format_index":null,"url":"https://test.test.com/abcd=fmp","manifest_url":"https://test.test.com/abcd=fmpr=fmp","protocol":"m3u8_native","audio_ext":"none","vbr":632,"abr":0},{"url":"https://test.test.com/abcd=fmp?abcd=11","format_id":"http-632","tbr":632,"width":320,"height":568,"protocol":"https","ext":"mp4","resolution":"320x568"},{"format_id":"http-950","format_index":null,"url":"https://test.test.com/abcd=fmp?abcd=15","manifest_url":"https://test.test.com/abcd3=fmpr=fmp","ext":"mp4","fps":null,"protocol":"https","resolution":"480x852"}],"thumbnails":[{"id":"thumb","url":"test.test.comtIUq.jpg?name=thumb","width":150,"height":150,"resolution":"150x150"},{"id":"small","url":"test.test.comIUq.jpg?name=small","width":383,"height":680,"resolution":"383x680"}]}
获取上面json的title 行, 截取前30个字符串,
formats 行,formats下很多行,取下面的 "protocol" 为"https"的平级url 和resolution
thumbnails行下的 "id"为 small 的url,
并把上面取到的(title行,formats中的url和resolution,thumbnails下的url)映射为json,返回
|
https://twitter.com/i/status/1516026810978373633 1.伪街时被绑架进行痴女化调教沦为公共人妖肉便器;2.援交时被贩卖到海外强制女体化改造沦为人妖妓女;3.女装时被老板发现胁迫调教开发成专属人妖性奴;4.调教时被女主锁死贞操带圈养洗脑成为人妖母狗;5. 购物时被女装店店长囚禁制作成强制高潮的人妖模特
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| {
"id":"144706695533335",
"title":"\u6296\u97f3\u5feb\u624b\u4e3b\u64ad\u798f",
"formats":[
{
"format_id":"hls-632",
"format_index":null,
"url":"https://test.test.com/abcd=fmp",
"manifest_url":"https://test.test.com/abcd=fmpr=fmp",
"protocol":"m3u8_native",
"audio_ext":"none",
"vbr":632,
"abr":0
},
{
"url":"https://test.test.com/abcd=fmp?abcd=11",
"format_id":"http-632",
"tbr":632,
"width":320,
"height":568,
"protocol":"https",
"ext":"mp4",
"resolution":"320x568"
},
{
"format_id":"http-950",
"format_index":null,
"url":"https://test.test.com/abcd=fmp?abcd=15",
"manifest_url":"https://test.test.com/abcd3=fmpr=fmp",
"ext":"mp4",
"fps":null,
"protocol":"https",
"resolution":"480x852"
}
],
"thumbnails":[
{
"id":"thumb",
"url":"test.test.comtIUq.jpg?name=thumb",
"width":150,
"height":150,
"resolution":"150x150"
},
{
"id":"small",
"url":"test.test.comIUq.jpg?name=small",
"width":383,
"height":680,
"resolution":"383x680"
}
]
}
|
– bin/xxx 输出 。提取
1
| {"id":"144706695533335","title":"\u6296\u97f3\u5feb\u624b\u4e3b\u64ad\u798f","formats":[{"format_id":"hls-632","format_index":null,"url":"https://test.test.com/abcd=fmp","manifest_url":"https://test.test.com/abcd=fmpr=fmp","protocol":"m3u8_native","audio_ext":"none","vbr":632,"abr":0},{"url":"https://test.test.com/abcd=fmp?abcd=11","format_id":"http-632","tbr":632,"width":320,"height":568,"protocol":"https","ext":"mp4","resolution":"320x568"},{"format_id":"http-950","format_index":null,"url":"https://test.test.com/abcd=fmp?abcd=15","manifest_url":"https://test.test.com/abcd3=fmpr=fmp","ext":"mp4","fps":null,"protocol":"https","resolution":"480x852"}],"thumbnails":[{"id":"thumb","url":"test.test.comtIUq.jpg?name=thumb","width":150,"height":150,"resolution":"150x150"},{"id":"small","url":"test.test.comIUq.jpg?name=small","width":383,"height":680,"resolution":"383x680"}]}
|
—- 点击download有响应输出json了。但页面没有进入新页面,并显示下载按钮。下面是json输出
1
| {"formats":[{"resolution":"320x568","url":"test.test.com/abcd=fmp/320x568/7uB0nnxyhIQwVJca.mp4?tag=12"},{"resolution":"480x852","url":"test.test.com/abcd=fmp/480x852/dGS1AqHlSBbBGY10.mp4?tag=12"},{"resolution":"720x1280","url":"test.test.com/abcd=fmp/720x1280/p6gZ3sv9Hx2JeRoL.mp4?tag=12"}],"thumb":"https://test.test.con/5hHPs-oOX2Vzp18.jpg?name=small","title":"\u676d\u5dde\u5c0f\u7389\u5c45 "}
|
下面是前端代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| <button id="download_btn" type="button" onclick="downloadVideo()">Download</button>
<script>
document.getElementById("download_btn").addEventListener("click", async function() {
const video_link = document.getElementById('video_link').value;
const data = { video_link: video_link };
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(data)
};
const response = await fetch('https://test.test.com/download', options);
const jsonData = await response.json();
if (response.ok) {
const videoUrls = jsonData.data.videos;
for (let i = 0; i < videoUrls.length; i++) {
const url = videoUrls[i];
const a = document.createElement("a");
a.href = url;
a.download = "video" + (i + 1);
a.innerHTML = "Download video " + (i + 1);
document.body.appendChild(a);
}
}
});
</script>
|
如何做到点击download按钮,打开新页面
显示对应视频相应分辨率的下载按钮。比如这个json含有3个视频 假如有7201280,480852,320568的分辨率 ,则按钮1显示: 下载7201280 按钮2显示,按钮2显示:下载480852, 按钮3显示: 下载320568。点击相应的按钮则 进入新页面打开视频。 比如点击下载7201280 进入新页面 url是 https://xxx.com/test/15/pu/vid/720x1280/testl6.mp4?tag=12 这样视频播放。右击点击下载7201280 选另存为也会保存视频。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| {
"formats": [
{
"resolution": "320x568",
"url": "https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/320x568/7uB0nnxyhIQwVJca.mp4?tag=12"
},
{
"resolution": "480x852",
"url": "https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/480x852/dGS1AqHlSBbBGY10.mp4?tag=12"
},
{
"resolution": "720x1280",
"url": "https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/720x1280/p6gZ3sv9Hx2JeRoL.mp4?tag=12"
}
],
"thumb": "https://pbs.twimg.com/ext_tw_video_thumb/1595954260465704960/pu/img/g5hHPs-oOX2Vzp18.jpg?name=small",
"title": "杭州小玉居家服务系 - #杭州 #杭州双飞 #杭州同城 #杭"
}
|
点击download按钮有响应了,也进入新页面,显示三个按钮了,页面但一直在转圈圈,地址栏 about:blank。感觉这样不是很友好。点击download按钮有响应了,也进入新页面,可以调用test.test.com/twitter/下的模板吗,或者传给模板 然后进行显示。
模板显示需求:
1 总体来说样式是最前面视频图片thumb, 中间部分视频title信息,最后面 按钮 显示
这三部分视觉看起来是 平行的。看起来好像都在一个区块里一样,显得很平整。
2 按钮1,按钮2,按钮3 等需要并列显示 不是并排显示。并在 这几个按钮的并列区域前面显示一个这个url视频的标题信息title。
在下面显示 ,显示最大分辨率的最大分辨率视频下载地址的二维码 QR码图片。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| <script src="https://cdnjs.cloudflare.com/ajax/libs/handlebars.js/4.7.6/handlebars.min.js"></script>
<script src="template.js"></script>
var videoTemplate = Handlebars.compile(`
<div class="video">
<img src="{{thumb}}" alt="{{title}}">
<div class="video-info">
<h2>{{title}}</h2>
<div class="buttons">
<a href="{{downloadUrl1}}">Button 1</a>
<a href="{{downloadUrl2}}">Button 2</a>
<a href="{{downloadUrl3}}">Button 3</a>
</div>
</div>
<img src="{{qrCodeUrl}}" alt="QR code">
</div>
`);
const videoTemplate = Handlebars.compile(document.querySelector('#video-template').innerHTML);
const videoData = {
"formats": [
{
"resolution": "320x568",
"url": "https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/320x568/7uB0nnxyhIQwVJca.mp4?tag=12"
},
{
"resolution": "480x852",
"url": "https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/480x852/dGS1AqHlSBbBGY10.mp4?tag=12"
},
{
"resolution": "720x1280",
"url": "https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/720x1280/p6gZ3sv9Hx2JeRoL.mp4?tag=12"
}
],
"thumb": "https://pbs.twimg.com/ext_tw_video_thumb/1595954260465704960/pu/img/g5hHPs-oOX2Vzp18.jpg?name=small",
"title": "杭州小玉居家服务系 - #杭州 #杭州双飞 "
}
qrCodeUrl: 'https://test.test.com/abcd=fmp',
renderTemplate: function(jsonData) {
// 渲染模板的代码
// 例如使用 jQuery 或者 JavaScript 动态创建元素并插入到页面中
// 可以使用 jsonData.thumb, jsonData.title, jsonData.formats 等数据来渲染模板
}
renderTemplate: function(jsonData) {
// 创建一个 div 元素用来显示视频信息
var container = $('<div>').addClass('video-container');
// 在 div 中添加视频图片
var thumb = $('<img>').attr('src', jsonData.thumb).appendTo(container);
// 在 div 中添加视频标题
var title = $('<h2>').text(jsonData.title).appendTo(container);
// 创建一个 div 元素用来显示按钮
var buttons = $('<div>').addClass('buttons').appendTo(container);
// 遍历 jsonData.formats 数组,创建按钮并添加到 buttons div 中
jsonData.formats.forEach(function(format) {
var button = $('<button>').text(format.resolution).appendTo(buttons);
button.on('click', function() {
// 点击按钮时打开视频链接
window.open(format.url);
});
});
//将container 添加到 body 中
container.appendTo('body');
}
|
hugo主题maupassant 现在已经做好文字页目录左侧栏显示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| #layouts/_default/single.html的关于侧边栏显示目录代码部分。
{{ if .Params.toc }}
<div class="clear" style="display: none">
<div class="toc-article">
<div class="toc-title">{{ i18n "toc" }}</div>
</div>
</div>
{{ end }}
#layouts/partials/toc.html 具体代码
{{ if or .Params.toc (and .Site.Params.toc (ne .Params.toc false)) -}}
<style type="text/css">
......
</style>
<div class="post-toc" style="position: absolute; top: 188px;">
<h2 class="post-toc-title">{{ i18n "toc" }}</h2>
<div class="post-toc-content">
{{.TableOfContents}}
</div>
</div>
<script type="text/javascript">
$(document).ready(function () {
var postToc = $(".post-toc");
if (postToc.length) {
var leftPos = $("#main").offset().left;
if (leftPos < 220) {
postToc.css({ "width": leftPos - 10, "margin-left": (0 - leftPos) })
}
var t = postToc.offset().top - 20,
a = {
start: {
position: "absolute",
top: t
},
process: {
position: "fixed",
top: 20
},
};
$(window).scroll(function () {
var e = $(window).scrollTop();
e < t ? postToc.css(a.start) : postToc.css(a.process)
})
}
if ($("#TableOfContents").children().length < 1) {
$(".post-toc").remove();
}
})
</script>
{{- end }}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| <button id="download_btn" type="button" onclick="downloadVideo()">Download</button>
<script>
async function downloadVideo() {
const video_link = document.getElementById('video_link').value;
const data = {video_link: video_link};
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(data)
};
const response = await fetch('https://testtest.com/download', options);
const result = await response.json();
console.log(result);
}
document.getElementById('download_btn').addEventListener('click', downloadVideo);
</script>
<script>
document.getElementById("download_btn").addEventListener("click", async function() {
const response = await fetch("https://testtest.com/download");
const jsonData = await response.json();
const videoUrls = jsonData.data.videos;
// 创建下载按钮
for (let i = 0; i < videoUrls.length; i++) {
const url = videoUrls[i];
const a = document.createElement("a");
a.href = url;
a.download = "video" + (i + 1);
a.innerHTML = "Download video " + (i + 1);
document.body.appendChild(a);
}
});
</script>
|
嗯,看着不错。我很疑惑,
第一次 fetch得到 json数据了。
const response = await fetch(‘https://testtest.com/api/process', options);
if (response.ok) {
为什么还要第二次 await fetch(‘https://testtest.com/download 这个?
这2次调用是分别取什么数据。
另外我之前按照你测试示例 ,点击download按钮 已经得到了json数据。await fetch填的是https://testtest.com/download。而不是https://testtest.com/api/process。
如果第一个是填https://testtest.com/api/process 。那我之前流程是不是错了。后端代码都要重新改。我后端的逻辑是:
点击 请求https://testtest.com/download 到 flask中@app.route("/download"中的download函数得到客户端传来的video_link, 执行函数gv, 并把video_link传给gv ,gv 调用@app.route /api/process 把video_link传给/api/process, /api/process把处理结果 返回直到html 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
<script>
async function downloadVideo() {
const video_link = document.getElementById('video_link').value;
const data = {video_link: video_link};
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(data)
};
const response = await fetch('https://testtest.com/download', options);
const result = await response.json();
console.log(result);
}
document.getElementById('download_btn').addEventListener('click', downloadVideo);
</script>
能这样吗?
还是按我之前的那个后端实现,点击 请求https://testtest.com/download 到 flask中@app.route("/download"中的download函数得到客户端传来的video_link, 执行函数gv, 并把video_link传给gv ,gv 调用@app.route /api/process 把video_link传给/api/process, /api/process把处理结果 返回直到html 。
curl --user-agent "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" -X POST -H "Content-Type: application/json" -d '{"video_link": "https://testtest.com/1529"}' https://www.test.com/download 报错 raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 2 (char 1) 你代码@app.route("/download"这部分是不是有问题
result = run(["./yt-dlp", url, "--dump-json", "--no-check-certificates", "--no-warnings"], stdout=PIPE, stderr=PIPE)
if result.returncode != 0:
return jsonify({'error': result.stderr.decode()}), 500
videos = [json.loads(line)['url'] for line in result.stdout.decode().split('\n') if line]
print(videos)
return jsonify({'data': {'videos': videos}})
result = run(["bin/xxx", url, "--dump-json", "--no-check-certificates", "--no-warnings"], stdout=PIPE, stderr=PIPE)
if result.returncode != 0:
return jsonify({'error': result.stderr.decode()}), 500
videos = [json.loads(line)['url'] for line in result.stdout.decode().split('\n') if line]
print(result)
print(videos)
result = json.loads(process.stdout.decode())
print(videos) ok有输出 。但result = json.loads(process.stdout.decode())报错。
result = json.loads(process.stdout.decode())
AttributeError: 'function' object has no attribute 'stdout',我看了下result
async function downloadVideo() {
const video_link = document.getElementById('video_link').value;
const data = {video_link: video_link};
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(data)
};
const response = await fetch('https://www.2urs.com/download', options);
const result = await response.json();
console.log(result);
}
//document.getElementById('download_btn').addEventListener('click', downloadVideo);
|
请仔细看题目,下面是首页代码是实现:点击download按钮有后端响应json了,也进入新页面,显示三个按钮了,页面但一直在转圈圈,地址栏 about:blank。感觉这样不是很友好。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| <button id="download_btn" type="button">Download</button>
<script>
document.getElementById("download_btn").addEventListener("click", async function() {
const video_link = document.getElementById('video_link').value;
const data = { video_link: video_link };
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(data)
};
const response = await fetch('https://www.2urs.com/download', options);
const jsonData = await response.json();
if (response.ok) {
const newWindow = window.open();
newWindow.document.write("<h1>Video Download</h1>");
console.log(jsonData);
console.log(jsonData.data);
const videoUrls = jsonData.formats;
for (let i = 0; i < videoUrls.length; i++) {
const video = videoUrls[i];
const button = document.createElement("button");
button.innerHTML = `Download ${video.resolution}`;
button.href = video.url;
button.onclick = function() {
newWindow.location.href = this.href;
}
newWindow.document.body.appendChild(button);
}
}
});
</script>
|
在我原来首页的代码基础上,怎么实现上面刚刚说的需求:点击首页download按钮,有响应了【比如后端会返回json含视频信息】,在原标签页上面,可以调用test.test.com/twitter/下的模板吗,或者传给模板 然后在原标签页上进行显示。
模板显示需求:
1 总体来说样式是最前面视频图片thumb, 中间部分视频title信息,最后面 按钮 显示
这三部分视觉看起来是 平行的。看起来好像都在一个区块里一样,显得很平整。
在我原来首页的代码基础上能举个例子吗?听说你很厉害
报错:Uncaught SyntaxError: Identifier ‘videoTemplate’ has already been declared。
我之前的代码逻辑是 。点击download按钮有响应了,也进入新页面,显示三个按钮了,页面但一直在转圈圈,地址栏 about:blank。感觉这样不是很友好。现在改为:点击download按钮有响应了,在原标签页上面,可以调用test.test.com/twitter/下的模板吗,或者传给模板 然后进行显示。
模板显示需求:
1 总体来说样式是最前面视频图片thumb, 中间部分视频title信息,最后面 按钮 显示
这三部分视觉看起来是 平行的。看起来好像都在一个区块里一样,显得很平整。
2 按钮1,按钮2,按钮3 等需要并列显示 不是并排显示。并在 这几个按钮的并列区域前面显示一个这个url视频的标题信息title。
在下面显示 ,显示最大分辨率的最大分辨率视频下载地址的二维码 QR码图片。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| //首页
<script src="https://cdnjs.cloudflare.com/ajax/libs/handlebars.js/4.7.6/handlebars.min.js"></script>
<script src="template.js"></script>
</head>
<script id="video-template" type="text/x-handlebars-template"></script>
<body>
......
//template.js
var videoTemplate = Handlebars.compile(`
<div class="video">
<img src="{{thumb}}" alt="{{title}}">
<div class="video-info">
<h2>{{title}}</h2>
<div class="buttons">
<a href="{{downloadUrl1}}">Button 1</a>
<a href="{{downloadUrl2}}">Button 2</a>
<a href="{{downloadUrl3}}">Button 3</a>
</div>
</div>
<img src="{{qrCodeUrl}}" alt="QR code">
</div>
`);
const videoTemplate = Handlebars.compile(document.querySelector('#video-template').innerHTML);
const video = {
thumb: 'https://test.test.con/5hHPs-oOX2Vzp18.jpg?name=small',
title: '杭州小玉居',
formats: [
{resolution: '320x568', url: 'test.test.com/abcd=fmp/320x568/7uB0nnxyhIQwVJca.mp4?tag=12'},
{resolution: '480x852', url: 'test.test.com/abcd=fmp/480x852/dGS1AqHlSBbBGY10.mp4?tag=12'},
{resolution: '720x1280', url: 'test.test.com/abcd=fmp/720x1280/p6gZ3sv9Hx2JeRoL.mp4?tag=12'}
],
qrCodeUrl: 'https://test.test.com/abcd=fmp'
}
renderTemplate: function(jsonData) {
var template = Handlebars.compile(document.querySelector("#video-template").innerHTML);
var html = template(jsonData);
document.querySelector("#video-container").innerHTML = html;
}
renderTemplate: function(jsonData) {
// 创建一个 div 元素用来显示视频信息
var container = $('<div>').addClass('video-container');
var thumb = $('<img>').attr('src', jsonData.thumb).appendTo(container);
var title = $('<h2>').text(jsonData.title).appendTo(container);
var buttons = $('<div>').addClass('buttons').appendTo(container);
jsonData.formats.forEach(function(format) {
var button = $('<button>').text(format.resolution).appendTo(buttons);
button.on('click', function() {
window.open(format.url);
});
});
container.appendTo('body');
}
|
请仔细看题目,下面是首页代码是实现:点击download按钮有后端响应json了,也进入新页面,显示三个按钮了,页面但一直在转圈圈,地址栏 about:blank。感觉这样不是很友好。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| <button id="download_btn" type="button">Download</button>
<script>
document.getElementById("download_btn").addEventListener("click", async function() {
const video_link = document.getElementById('video_link').value;
const data = { video_link: video_link };
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(data)
};
const response = await fetch('https://www.2urs.com/download', options);
const jsonData = await response.json();
if (response.ok) {
const newWindow = window.open();
newWindow.document.write("<h1>Video Download</h1>");
console.log(jsonData);
console.log(jsonData.data);
const videoUrls = jsonData.formats;
for (let i = 0; i < videoUrls.length; i++) {
const video = videoUrls[i];
const button = document.createElement("button");
button.innerHTML = `Download ${video.resolution}`;
button.href = video.url;
button.onclick = function() {
newWindow.location.href = this.href;
}
newWindow.document.body.appendChild(button);
}
}
});
</script>
|
在我原来首页的代码基础上,怎么实现上面刚刚说的需求:点击首页download按钮,有响应了【比如后端会返回json含视频信息】,在原标签页上面,可以调用test.test.com/twitter/下的模板吗,或者传给模板 然后在原标签页上进行显示。
模板显示需求:
1 总体来说样式是最前面视频图片thumb, 中间部分视频title信息,最后面 按钮 显示
这三部分视觉看起来是 平行的。看起来好像都在一个区块里一样,显得很平整。
在我原来首页的代码基础上能举个例子吗?听说你很厉害
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| 点download按钮 后端响应返回
{"formats":[{"resolution":"320x568","url":"test.test.com/abcd=fmp/320x568/7uB0nnxyhIQwVJca.mp4?tag=12"},{"resolution":"480x852","url":"test.test.com/abcd=fmp/480x852/dGS1AqHlSBbBGY10.mp4?tag=12"},{"resolution":"720x1280","url":"test.test.com/abcd=fmp/720x1280/p6gZ3sv9Hx2JeRoL.mp4?tag=12"}],"thumb":"https://test.test.con/5hHPs-oOX2Vzp18.jpg?name=small","title":"\u676d\u5dde\u5c0f\u7389\u5c45 "}
如何要js 获取 resolution 最大值的url ,比如比如720x1280的url test.test.com/abcd=fmp/480x852/dGS1AqHlSBbBGY10.mp4?tag=12
然后输出下面内容
<div class="text-center"> <p class="qrcode-p">扫描下面的QR码,直接下载到您的智能手机或平板电脑!</p> </div>
<div class="col-fd-5 col-centered qrcode">
<div id="qrcode"></div>
<script src="/js/qrcode.min.js"></script> <script type="text/javascript">
new QRCode(document.getElementById("qrcode"),{
text: "https://video.twimg.com/ext_tw_video/1595954260465704960/pu/vid/720x1280/p6gZ3sv9Hx2JeRoL.mp4?tag=12",
width: 120,
height: 120,
correctLevel : QRCode.CorrectLevel.L
});
</script>
</div>
你可以在
const response = await fetch('testurl', options);
....
if (!response.ok) {
.......
}
try {
const jsonData = await response.json();
.......
document.body.appendChild(container);
} catch (error) {
.......
});
|
请仔细看题,为什么把createQRCode(maxResolutionUrl);放在document.body.appendChild(container);前面执行。
html中相关createQRCode的源码
不会出现在
里面。而是出现在他前面。
下面我提供的js代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| const response = await fetch('testurl', options);
....
if (!response.ok) {
.......
}
try {
if(container == null) {
container = document.createElement("div");
container.setAttribute("id", "container");
container.classList.add("container");
.......
const jsonData = await response.json();
.......
container.appendChild(imageDiv);
container.appendChild(titleDiv);
container.appendChild(buttonDiv);
.......
createQRCode(maxResolutionUrl);
document.body.appendChild(container);
} catch (error) {
.......
function createQRCode(url) {
const container = document.createElement("div");
container.classList.add("text-center");
.......
container.appendChild(script);
document.body.appendChild(container);
});
|
怎样设置按钮颜色 ,显示为深绿色 移到按钮上为浅绿色,按钮间隔为5,宽221 高22 在原来css的基础上改 .button-div { display: flex; align-items: center; justify-content: flex-end; flex-direction: column; }
也就是说我们之前js直接生成的样式不方便维护,用js生成的html只添加一些类名, 去引用CSS中对应的样式。使更方便维护管理 style 样式。
那你看下我这个代码怎样改下,使 js生成的html只添加一些类名, 去引用CSS中对应的样式。需求是:按钮变成上 中 下 这样竖着排 , 然后这部分按钮区块跟图片 、titl文字、 横着排 ,达到左边图片、 中间 title文字、 右边是按钮区块。 同时请给出对应的css样式。
请仔细看题,为什么把createQRCode(maxResolutionUrl);放在document.body.appendChild(container);前面执行。
html中相关createQRCode的源码
不会出现在
里面。而是出现在他前面。
下面我提供的js代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| const response = await fetch('testurl', options);
....
if (!response.ok) {
.......
}
try {
if(container == null) {
container = document.createElement("div");
container.setAttribute("id", "container");
container.classList.add("container");
.......
const jsonData = await response.json();
.......
container.appendChild(imageDiv);
container.appendChild(titleDiv);
container.appendChild(buttonDiv);
.......
createQRCode(maxResolutionUrl);
document.body.appendChild(container);
} catch (error) {
.......
function createQRCode(url) {
const container = document.createElement("div");
container.classList.add("text-center");
.......
container.appendChild(script);
document.body.appendChild(container);
});
---
.post-title
h1, h2, h3, h4, h5, h6 {
font-family: oswaldbook,sans-serif;
color: #3d3d3d;
font-weight: 400;
}
font-weight: bold;
.post-content
p {
font-family: inherit;
font-weight: normal;
font-size: 1.2em;
line-height: 1.6;
margin-bottom: 1.25em;
text-rendering: optimizeLegibility;
}
font-weight: bold;
.post-content 408
padding-left: 35px
|
–
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| {{- range where .Site.Pages "Type" "page" }}
<url>
<loc>{{ .Permalink }}</loc>{{ if not .Lastmod.IsZero }}
<lastmod>{{ safeHTML ( .Lastmod.Format "2006-01-02T15:04:05-07:00" ) }}</lastmod>
{{ if .Params.isHome }}
<changefreq>daily</changefreq>
<priority>1.0</priority>
{{ else if .Params.isPost }}
<changefreq>monthly</changefreq>
<priority>0.7</priority>
{{ else }}
<changefreq>monthly</changefreq>
<priority>0.5</priority>
{{ end }}
</url>
{{- end -}}
{{- range where .Site.RegularPages "Type" "post" }}
<url>
<loc>{{ .Permalink }}</loc>{{ if not .Lastmod.IsZero }}
<lastmod>{{ safeHTML ( .Lastmod.Format "2006-01-02T15:04:05-07:00" ) }}</lastmod>
{{ if .Params.isTag }}
<changefreq>Weekly</changefreq>
<priority>0.5</priority>
{{ else if .Params.isCategory }}
<changefreq>Weekly</changefreq>
<priority>0.5</priority>
{{ else }}
<changefreq>monthly</changefreq>
<priority>0.5</priority>
{{ end }}
</url>
{{- end -}}
</urlset>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
| {{ printf "<?xml version=\"1.0\" encoding=\"utf-8\" standalone=\"yes\"?>" | safeHTML }}
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xhtml="http://www.w3.org/1999/xhtml">
{{- range where .Site.Pages "Type" "page" }}
<url>
<loc>{{ .Permalink }}</loc>{{ if not .Lastmod.IsZero }}
<lastmod>{{ safeHTML ( .Lastmod.Format "2006-01-02T15:04:05-07:00" ) }}</lastmod>{{ end }}{{ with .Sitemap.ChangeFreq }}
<changefreq>{{ . }}</changefreq>{{ end }}{{ if ge .Sitemap.Priority 0.0 }}
<priority>{{ .Sitemap.Priority }}</priority>{{ end }}
</url>
{{- end -}}
{{- range where .Site.RegularPages "Type" "post" }}
<url>
<loc>{{ .Permalink }}</loc>{{ if not .Lastmod.IsZero }}
<lastmod>{{ safeHTML ( .Lastmod.Format "2006-01-02T15:04:05-07:00" ) }}</lastmod>{{ end }}{{ with .Sitemap.ChangeFreq }}
<changefreq>{{ . }}</changefreq>{{ end }}{{ if ge .Sitemap.Priority 0.0 }}
<priority>{{ .Sitemap.Priority }}</priority>{{ end }}
</url>
{{- end -}}
{{- range .Data.Pages -}}
{{- if eq .Kind "taxonomy" }}
<url>
<loc>{{ .Permalink }}</loc>{{ if not .Lastmod.IsZero }}
<lastmod>{{ safeHTML ( .Lastmod.Format "2006-01-02T15:04:05-07:00" ) }}</lastmod>{{ end }}{{ with .Sitemap.ChangeFreq }}
<changefreq>{{ . }}</changefreq>{{ end }}{{ if ge .Sitemap.Priority 0.0 }}
<priority>{{ .Sitemap.Priority }}</priority>{{ end }}
</url>
{{- end -}}
{{- end }}
</urlset>
.container {
width:1350px;
padding:0 60px;
margin:0 auto;
}
#secondary {
float:right;
width:245px;
border-left:1px solid #ddd;
padding-left:35px;
word-wrap:break-word;
display:block;
padding-top:10px;
}
.post {
padding:25px 0 15px;
padding-left:66px
}
.post-title {
font-family: oswaldbook,sans-serif;
color: #3d3d3d;
font-weight: bold;
}
.post-title a, .keyword {
color:#222226;
font-weight: 530;
}
#nav-menu a {
display:inline-block;
margin-right:-1px;
padding:0 1em;
height:32px;
line-height:32px;
color:#0f0f0f;
}
.post-content {
font-family: inherit;
font-weight: normal;
line-height: 1.6;
margin-bottom: 1.25em;
text-rendering: optimizeLegibility;
}
.widget-title {
color:#323333;
line-height:2.7;
margin-top:0;
font-size:16px;
border-bottom:1px solid #ddd;
display:block;
}
body{
color: rgba(0,0,0,.75);
font-family: Lato,-apple-system,SF UI Text,Arial,PingFang SC,Hiragino Sans GB,Microsoft YaHei,WenQuanYi Micro Hei,sans-serif;
font-variant-ligatures: common-ligatures;
line-height: 1.67;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
a, button.submit {
color:#323333;
text-decoration:none;
-webkit-transition:all .1s ease-in;
-moz-transition:all .1s ease-in;
-o-transition:all .1s ease-in;
transition:all .1s ease-in;
}
#header {
padding:18px 0 0;
text-align:left;
}
#logo {
/**
font:bold 42px/1.12 "Times New Roman", Georgia, Times, sans-serif;
**/
font-size: 31.5px;
font-weight: bold;
color:#363535;
}
<div class="highlight"><pre tabindex="0" style="color:#d0d0d0;background-color:#202020;-moz-tab-size:4;-o-tab-size:4;tab-size:4"><code class="language-bash" data-lang="bash"><span style="display:flex"><span><span style="color:#cd2828;font-weight:700">
</span></span></code></pre> </div>
|
如果hugo设置了高亮显示 md中的代码,用手机浏览的时候,可以适配浏览。不会超宽度。可以左右滑动的那种,代码区有个左右的滑动条。
但表格却不会,导致不能在手机中适配浏览,表格怎样做到像代码那样也适配浏览 带左右滑动条的那种。
f.write("|优惠码|折扣|更新时间|官网|中国官网|\n")
f.write("|-----|----|----------|----|-------|\n")
不修改,google 收录验证。
https://www.2urs.com/post/welfare/bwg/bandwagonHost-coupons2023-01-29/
Googlebot 智能手机版 通过,有时不通过。
错误:
其他错误
样式表
https://cdn.bootcdn.net/ajax/libs/fancybox/3.5.7/jquery.fancybox.min.css
robots.txt 已禁止 Googlebot 进行抓取
其他
https://googleads.g.doubleclick.net/pagead/html/r20230124/r20190131/zrt_lookup.html
robots.txt 已禁止 Googlebot 进行抓取
脚本
https://pagead2.googlesyndication.com/pagead/managed/js/adsense/m202301230101/show_ads_impl_with_ama_fy2021.js?client=ca-pub-2094041867720566&plah=www.2urs.com&bust=31071854
Uncaught Error: Invalid repo: “your github repo” at https://utteranc.es/utterances.6ec01640.js:1:776 at https://utteranc.es/utterances.6ec01640.js:1:998
https://utteranc.es/utterances.6ec01640.js:0
我试了下curl 加上Origin 和 Referer 确实还是可以请求服务端 ok 。 要怎么做到? 在别人他自己的网站请求我服务端,肯定不能响应。利用我的服务器资源,直接给他结果。
在服务端生成一个CSRF token ,JavaScript在页面加载时请求服务端获取token , 在下面的代码上要改下哪里
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| from flask import Flask, request, jsonify
import requests
import json
import qrcode
from subprocess import run, PIPE
app = Flask(__name__)
@app.route("/download", methods=["POST"])
def download():
video_link = request.json["video_link"]
response = requests.get(video_link)
html = response.text
resolutions = []
for line in html.split("\n"):
if "video_link" in line:
url = line.split('"')[1]
resolution = line.split('"')[3]
resolutions.append({"url": url, "resolution": resolution})
return parse_video_url(video_link)
def parse_video_url(video_link):
video_link = request.json["video_link"]
url = "http://127.0.0.1:8010/api/process"
params = {'video_link': video_link}
response = requests.get(url, params=params)
if response.status_code == 200:
return response.json()
else:
return "Error occurred"
@app.route('/api/process', methods=['GET'])
def process():
url = request.args.get('video_link')
if not url:
return jsonify({'error': 'Missing url'}), 400
result = run(["./bin/test", url, "--dump-json", "--no-check-certificates", "--no-warnings"], stdout=PIPE, stderr=PIPE)
if result.returncode != 0:
return jsonify({'error': result.stderr.decode()}), 500
videos = [json.loads(line)['url'] for line in result.stdout.decode().split('\n') if line]
print(result)
print(videos)
result = json.loads(result.stdout.decode())
title = result['title'][:30]
formats = [{'url': item['url'], 'resolution': item['resolution']} for item in result['formats'] if item['protocol'] == 'https']
thumb = next((item['url'] for item in result['thumbnails'] if item['id'] == 'small'), None)
data = {'title': title, 'formats': formats, 'thumb': thumb}
print(data)
return jsonify(data)
if __name__ == "__main__":
app.run(debug=True,host='127.0.0.1', port=8010 )
|
— 抖音 无水印
9.99 bnq:/ 60秒快速入睡法,还能缓解焦虑# 医生 # 失眠 # 睡眠 # 健康 # 科普 https://v.douyin.com/BrpBUL2/ 复制此链接,打开Dou音搜索,直接观看视频!
https://ouotool.com/dy?url=https://v.douyin.com/BrUt6em/ cmd :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| curl "https://ouotool.com/dy?url=https://v.douyin.com/BrUt6em/" ^
-H "authority: ouotool.com" ^
-H "accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9" ^
-H "accept-language: zh-CN,zh;q=0.9" ^
-H "cookie: _ga=GA1.1.2034673096.1675424464; XSRF-TOKEN=eyJpdiI6IjBnRVgzbGwxbmxpK0JnQlwvN3FcL0NRUT09IiwidmFsdWUiOiJHQUxLVEwxMTFVVmlCdXdPdlg5RTJ6enlOdVpjejI4YU9RNGFETlwvckFuSTIrSFwvTTN6aXhzSVJ6WGZPR1l4SmMiLCJtYWMiOiIzZWY4YTFmMTIxNGU0NzExNzc0Y2M0ZWM3MDFkY2RkYjY2ZmU0ZWY1M2RiOGFmNGViYTk0NDEzMTE0OWVlMzI2In0^%^3D; ouo_session=eyJpdiI6IlZFcjVvY05jTUJnVUpkbmVBVVwvRXZBPT0iLCJ2YWx1ZSI6IkVkc0dXN3hkQldFdFlxZ2ptVm9aalQ5cjNkXC9KaTQycWN6UVVvYndRc0V3b1VKa3FtV0Zvc1lHRDMzYTYzNUh4IiwibWFjIjoiODgwMTkxOGU0ZGYxZjZhNzg0YjE4MzVlY2U4MWQ4MTVmMTdhN2M5YWQ4ZTZhNzgyYjdmZDI0OTFiZWFjNzJjNSJ9; _ga_0HEDDW9N0M=GS1.1.1675429891.2.1.1675431604.0.0.0" ^
-H "sec-ch-ua: ^\^"Not_A Brand^\^";v=^\^"99^\^", ^\^"Google Chrome^\^";v=^\^"109^\^", ^\^"Chromium^\^";v=^\^"109^\^"" ^
-H "sec-ch-ua-mobile: ?0" ^
-H "sec-ch-ua-platform: ^\^"Windows^\^"" ^
-H "sec-fetch-dest: document" ^
-H "sec-fetch-mode: navigate" ^
-H "sec-fetch-site: cross-site" ^
-H "sec-fetch-user: ?1" ^
-H "upgrade-insecure-requests: 1" ^
-H "user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36" ^
--compressed
|
可以 但慢
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| curl "https://ouotool.com/dy?url=https://v.douyin.com/BrUt6em/" ^ -H "user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
---
url=https%3A%2F%2Fv.douyin.com%2FBrUt6em%2F&captcha=uxgk cmd
curl "https://www.daimadog.com/wp-content/themes/mytheme/action/dyjx.php" ^
-H "Accept: application/json, text/javascript, */*; q=0.01" ^
-H "Accept-Language: zh-CN,zh;q=0.9" ^
-H "Connection: keep-alive" ^
-H "Content-Type: application/x-www-form-urlencoded; charset=UTF-8" ^
-H "Cookie: PHPSESSID=3neaakiontb2hpa8t238qt2ua2" ^
-H "Origin: https://www.daimadog.com" ^
-H "Referer: https://www.daimadog.com/douyin" ^
-H "Sec-Fetch-Dest: empty" ^
-H "Sec-Fetch-Mode: cors" ^
-H "Sec-Fetch-Site: same-origin" ^
-H "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36" ^
-H "X-Requested-With: XMLHttpRequest" ^
-H "sec-ch-ua: ^\^"Not_A Brand^\^";v=^\^"99^\^", ^\^"Google Chrome^\^";v=^\^"109^\^", ^\^"Chromium^\^";v=^\^"109^\^"" ^
-H "sec-ch-ua-mobile: ?0" ^
-H "sec-ch-ua-platform: ^\^"Windows^\^"" ^
--data-raw "url=https^%^3A^%^2F^%^2Fv.douyin.com^%^2FBrUt6em^%^2F&captcha=uxgk" ^
--compressed
|
报错 curl “https://www.daimadog.com/wp-content/themes/mytheme/action/dyjx.php" ^ –data-raw “url=https^%^3A^%^2F^%^2Fv.douyin.com^%^2FBrUt6em^%^2F&captcha=uxgk”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| var cnip=''
function ipcn(){
if(visibl){
fetch('https://forge.speedtest.cn/api/location/info',{referrerPolicy: 'no-referrer'})
.then(response => response.json())
.then(data =>{
var tag = document.getElementById("ipcn")
tag.innerText=data['ip']+' '+data['province']+' '+data['city']+' '+data['distinct']+' '+data['isp']
if(data['ip'] !== cnip){
tag.style.color=''
ckip(data['ip'],tag)
}
cnip=data['ip'];
});
}
setTimeout(ipcn,5000)
}
var gbip=""
function ipgb(){
if(visibl){
fetch('https://api-ipv4.ip.sb/geoip',{referrerPolicy: 'no-referrer'})
.then(response => response.json())
.then(data =>{
var tag = document.getElementById("ipgb")
tag.innerText=data['ip']+' '+CountryCode_Zh_cn[data['country_code']]+' '+data['isp']
if(data['ip'] !== gbip){
tag.style.color=''
ckip(data['ip'],tag)
}
gbip=data['ip'];
});
}
setTimeout(ipgb,refresh_lay)
https://net.ljxnet.cn/main.js?1
参考:
https://ipinfo.io/ 日均IP≈66000
whatismyipaddress.com 日均IP≈318000
https://www.ipip.net/ 日均IP≈66000
zh-hans.ipshu.com IP≈13800
ip111.cn 预估日均IP≈56400
https://ip233.cn/ 0
从国内测试
117.147.74.246 中国 杭州
这是您访问国内网站所使用的IP
从国外测试
您访问没有被封的国外网站所使用的IP
从谷歌测试
这是您访问谷歌,Facebook,Twitter等网站所使用的IP
##IPv4 数据产品,IPv4 地级市精度库,IPv4 国内区县库,IPv4 国内高精度定位,IPv4 应用场景,IPv4 CDN/DNS 专版库,IPv4 查询接口服务,IPv4 代理风险识别,IPv6 数据产品,IPv6 地理位置库,IPv6 国内区县库,IPv6 应用场景,IPv6 查询接口服务,网络安全基础数据,IPv4 风险画像,全球基站 IPv4 数据,全球 IDC IPv4 数据,IP Whois 数据,IPv4 ReverseDNS 数据,ASN & BGP IP 库,全网 IPv4 端口数据
https://github.com/ljxi/NetworkPanel 测速测试您的网速,多地查询您的IP地址,同时具备网络延迟实时检测,流量杀手,流量消耗器,流量消失器
支持定量完成,支持多线程,适配iOS后台运行。
https://ip.jackjyq.com/ django框架 查询我的 IP 地址、归属地、设备类型、操作系统、浏览器版本、屏幕分辨率、经纬度及地理位置。
https://github.com/suncle1993/ip_query_http_service flask框架
|
18 yandex 源码
Alice AI助手(小爱同学?)、地图服务(百度地图?)、网盘服务(百度云盘?)、团购服务(美团?)、广告服务(百度排名?)、支付系统(支付宝?、旅游(去哪儿?)、打车(滴滴?)、邮箱(http://126.com?)、云服务(阿里云?)、电商(淘宝?)、协同办公(金山云?)、数据分析、还有它的CI/CD系统 ,我们从泄漏出来的压缩包名称中看到,这些服务都包含全了。这下好,大半个中国互联网大佬替代方案都搬回家了,可惜的都没有训练好的模型和二进制数据。
可以看到yandex的技术栈不光c++,还有Go语言、java和python,而且我这边迅速统计了一下,python和java的代码都不少。python后台多是django的代码。go语言我还没有深入,不确定用的什么框架。以下是yandex的源码图片,大家可以看一看。另外我放上了统计各编程源码占有量的饼状图时用到的python源码图片,有需要的可以自取。
搜索引擎方面,中文内容,必硬第一,白度第二
全球方面,能用上谷歌的不说了。但是搜索那些让你得关门的内容, yandex的搜索引擎基本上属于你不使用魔法,最好的选择,没有之一。
magnet:?xt=urn:btih:7e0ac90b489baee8a823381792ec67d465488fef&dn=yandexarc&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2F9.rarbg.to%3A2920&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2Fexodus.desync.com%3A6969&tr=udp%3A%2F%2Fbt1.archive.org%3A6969%2Fannounce&tr=udp%3A%2F%2Fbt2.archive.org%3A6969%2Fannounce&tr=udp%3A%2F%2Fopen.demonii.com%3A1337%2Fannounce
1
2
| snapsave.app 15932 12061 VN 777
|
